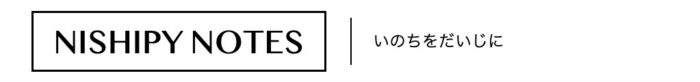

AWSしか触ったことのない私が、BigQueryに読み込んだデータを、Google Datalabを用いて可視化してみます。
1. やりたいこと
- BigQueryにデータを読み込み(前回やった)
- BIgQuery上のデータを、Datalabで可視化
- Datalabで可視化した結果を、Cloud Storageに出力
2. 前提知識
Cloud Datalab
インタラクティブな分析ツールです。ほぼJupyter Notebookと同じです。
GCPの他のサービスとの連携が容易になるように、よく使うライブラリは予めインストールされています。
Cloud Datalab自体は無料ですが、GCE(Google Compute Engine, いわゆるIaaS)上で動くので、GCEインスタンスの利用料が課金されます。
詳細は、下記リンクを参照ください。

Redirecting...
cloud.google.com
3. 扱うデータ
Twitter APIを用いて収集した、自身のTweetデータを扱います。
詳しい手順は以下の記事を参照ください。
Pythonで自分のツイートをすべて取得する方法と、いいねが多いツイートの特徴
Nishipy本ブログ用に作ったTwitterアカウントのフォロワーが1000人を超えました!良い節目ですので、自分の今までのツイートをスクレイピングします。そして、"いいね"数が多いツイートの傾向について、見ていきます。...(続く)
nishipy.com
4. やってみる
データの読み込み
せっかくなので、前回作った仕組みを使って、読み込んでみます。
Cloud Functionsで、GCSにアップロードしたCSVデータをBigQueryに読み込む
NishipyAWSしか触ったことのない私が、最近GCP(Google Cloud Platform)を使う機会があったのでメモします。Cloud Functionsのチュートリアルとしてご覧ください。1. やりたいことCl...(続く)
nishipy.com
- Cloud Storageにデータをアップロード
- Cloud Functionsにより、BigQueryへデータ読み込み
Stackdriverのログは、以下の通り。正常に実行できた模様。

- BigQuery上で確認
対象テーブルをみてみるとこんな感じです。
Cloud Datalabでの可視化
Cloud Datalab用インスタンスの作成
- Cloud Shellからデプロイ
- インスタンス名には、
datalab-instanceを指定 - zoneには、東京リージョンのゾーン
asia-northeast1-aを指定
|
1 2 |
datalab create datalab-instance --zone asia-northeast1-a |
Cloud Datalab用インスタンスへの接続
- 以下のコマンドで接続
|
1 2 |
datalab connect datalab-instance |
- インスタンスへSSH接続し、Datalab起動
完了すると、以下のメッセージが表示されます。

- 上記メッセージに従い、8081ポートを指定してプレビュー表示
これで、Datalabが開きます。
データ可視化
ここからは、DatalabでNotebookを作成してコードを書いていきます。↓のような感じ。
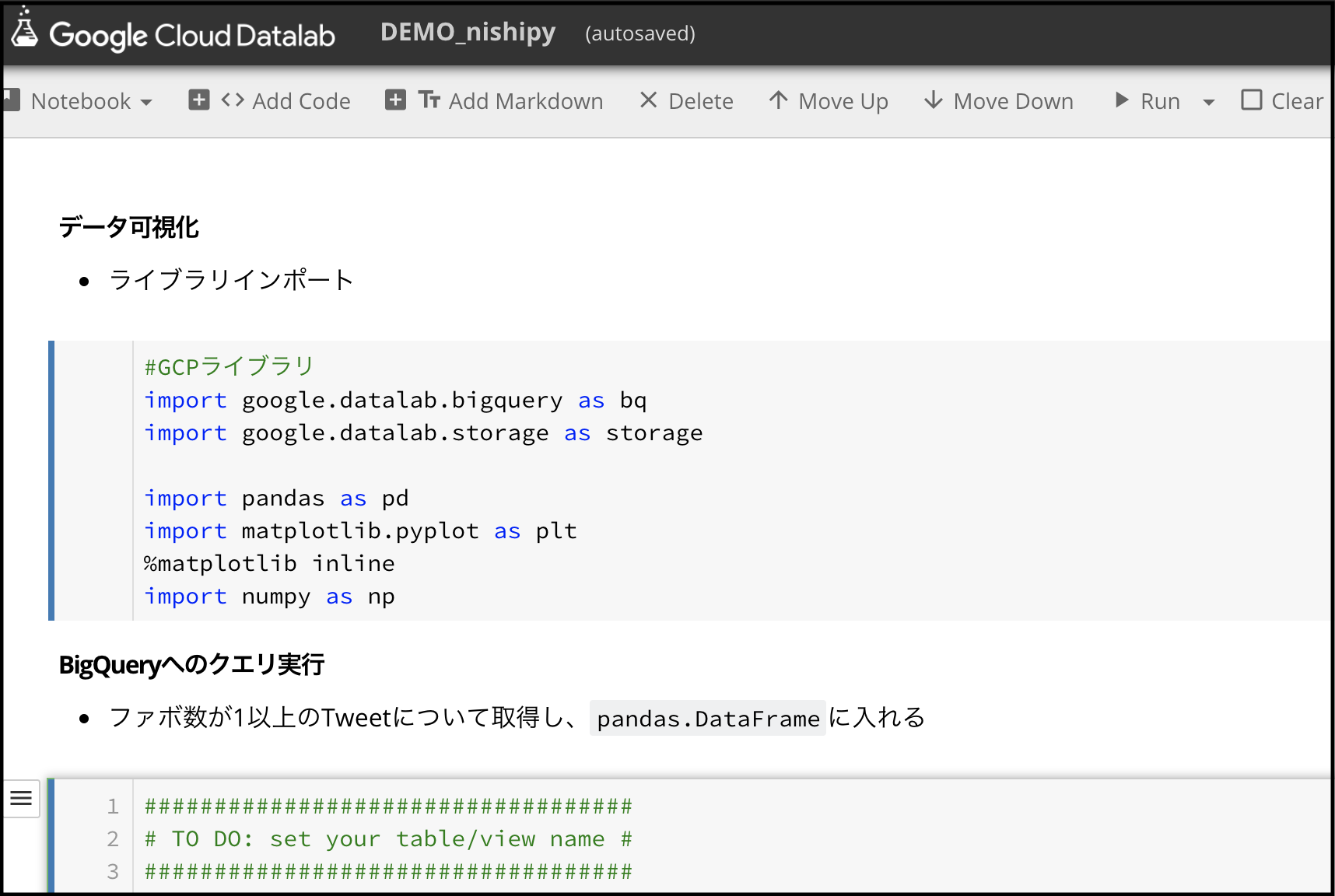
- ライブラリインポート
1234567#GCPライブラリimport google.datalab.bigquery as bqimport google.datalab.storage as storageimport pandas as pdimport seaborn as sns
なお、
Google Cloud Client Library for Pythonの詳細は、こちら。

301 Moved Permanently
googleapis.github.io
- BigQueryへのクエリ実行
クエリに結果は、pandas.DataFrameにいれます。123456789101112######################### TO DO: set variables #########################project_id = '[YOUR PROJECT ID]'dataset_name = '[YOUR DATASET NAME]'table_name = '[YOUR TABLE NAME]'query = "SELECT tweet_text, n_favorited, hasImage FROM `{}.{}.{}` ".format(project_id, dataset_name, table_name)bqjob = bq.Query(query)df = bqjob.execute(output_options=bq.QueryOutput.dataframe()).result()df.head() - グラフで可視化した結果を、Cloud Storageに格納
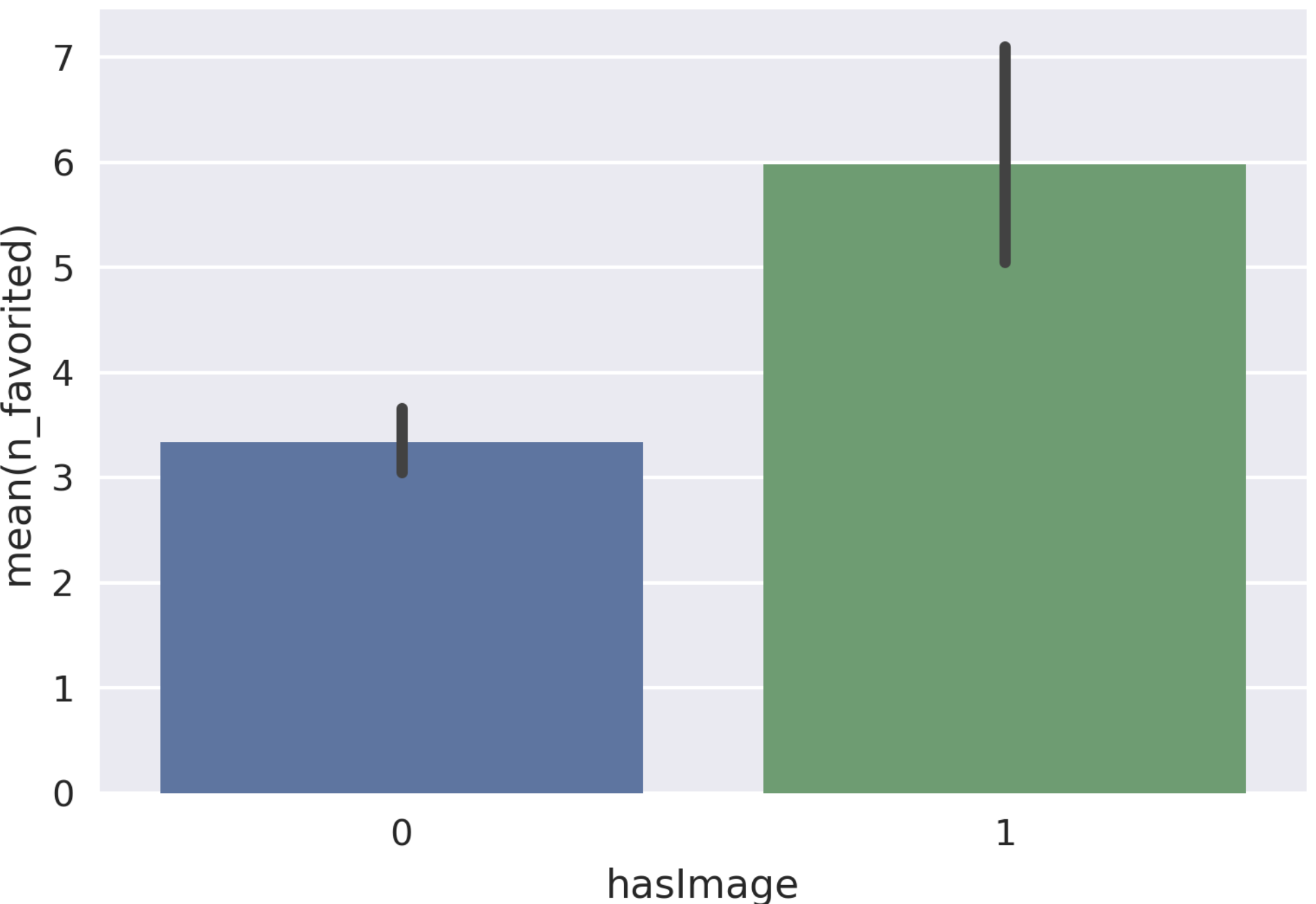
- 適当に可視化し、カレントディレクトリにグラフの画像を保存
1234# Tweetの画像有無(1 or 0)と、ファボ数の関係を可視化sns.barplot(x="hasImage", y="n_favorited", data=df)plt.savefig("demo_chart.png",format = 'png', dpi=300)- グラフをpng形式で、Cloud Storageに保存
123456789101112131415################################ TO DO: set your bucket name ################################bucket_name = '[YOUR BACKET NAME]'bucket_path = 'gs://{}'.format(bucket_name)upload_filename = 'demo_chart.png'png_path = 'demo_chart.png'bucket = storage.Bucket(bucket_name)upload_object = bucket.object(upload_filename)with open (png_path,'rb') as f:upload_object.write_stream(f.read(),content_type='image/png')print('Uploaded') - Cloud Storageバケットを確認
アップロード先のバケットを確認すると、先ほど作成したグラフがdemo-chart.pngとして格納されているはずです。
5. 今後やりたいこと
- BigQueryとGoogle Data Portalを連携
以上.

コメント