
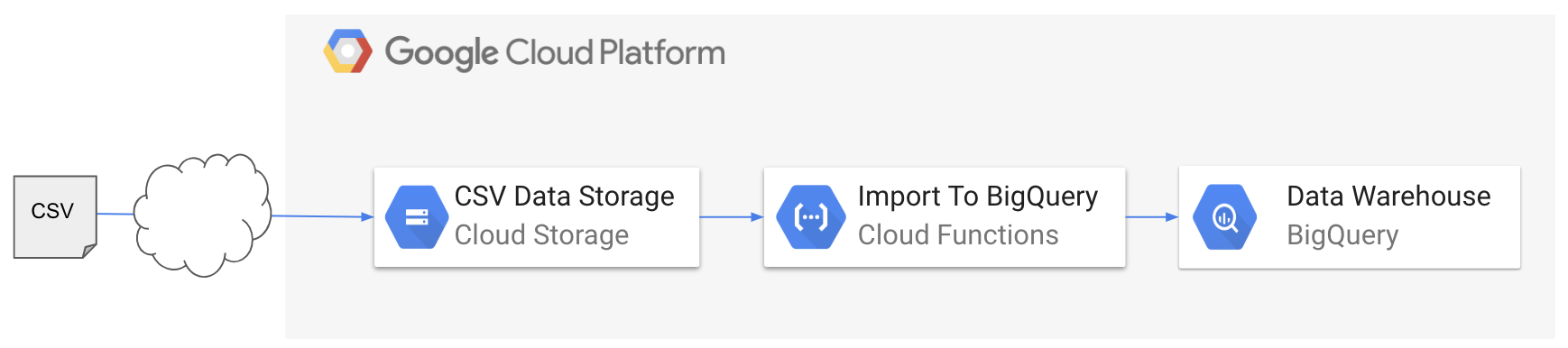
1. やりたいこと
- Cloud Storageにデータをアップロード
- データアップロードをトリガーとしてCloud Functions起動
- Cloud Functionsにより、データをBigQueryにインポート
2. 予備知識の復習
一般的なクラウドサービスについては、↓の記事にも書いています。

Cloud Storage
オブジェクトストレージのクラウドサービスであり、AWSで言う所のS3です。
詳細は、下記リンクを参照ください。

Cloud Functions
GCPの提供するFaaSであり、AWSで言う所のLambdaです。
イベントドリブンのサーバーレスアーキテクチャを実現できます。
詳細は、下記リンクを参照ください。
BigQuery
データウェアハウスのクラウドサービスであり、AWSで言う所のAthenaだと思います。
3. やってみる
Cloud Storageバケットの用意
Cloud Storageでは、S3と同様にバケットと呼ばれるデータの入れ物を作成します。
データへのアクセス権限の設定を省略するために、今回はバケットをインターネット上に公開することにします。
- バケットの作成
RegionalまたはMulti-Regionalを選択して、作成します。
- バケットの公開
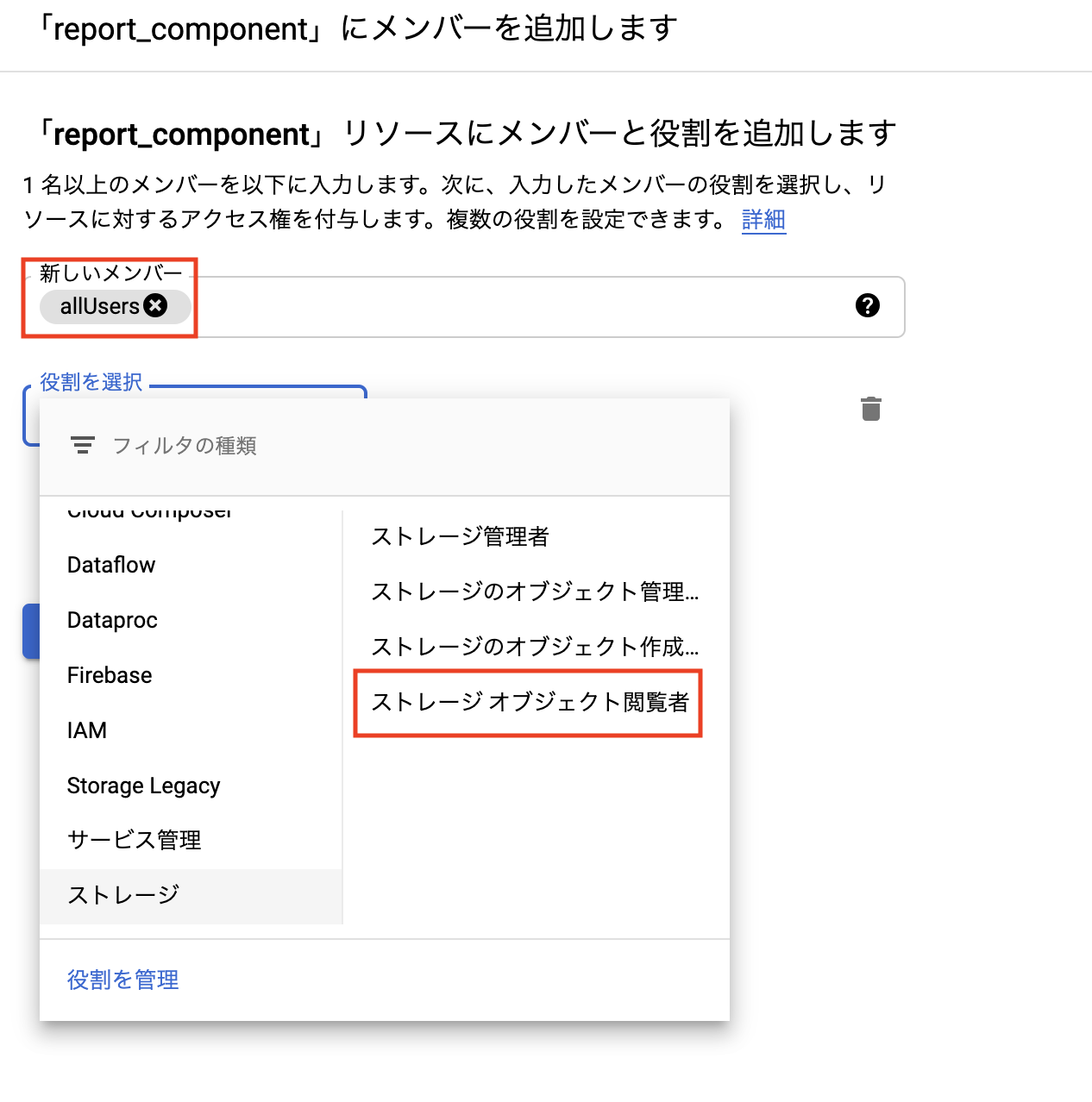
下記の手順で、バケットをインターネットに公開します。- 権限タブからユーザの追加を選択

-
「allUser」に対して、ストレージ閲覧ロールを付与
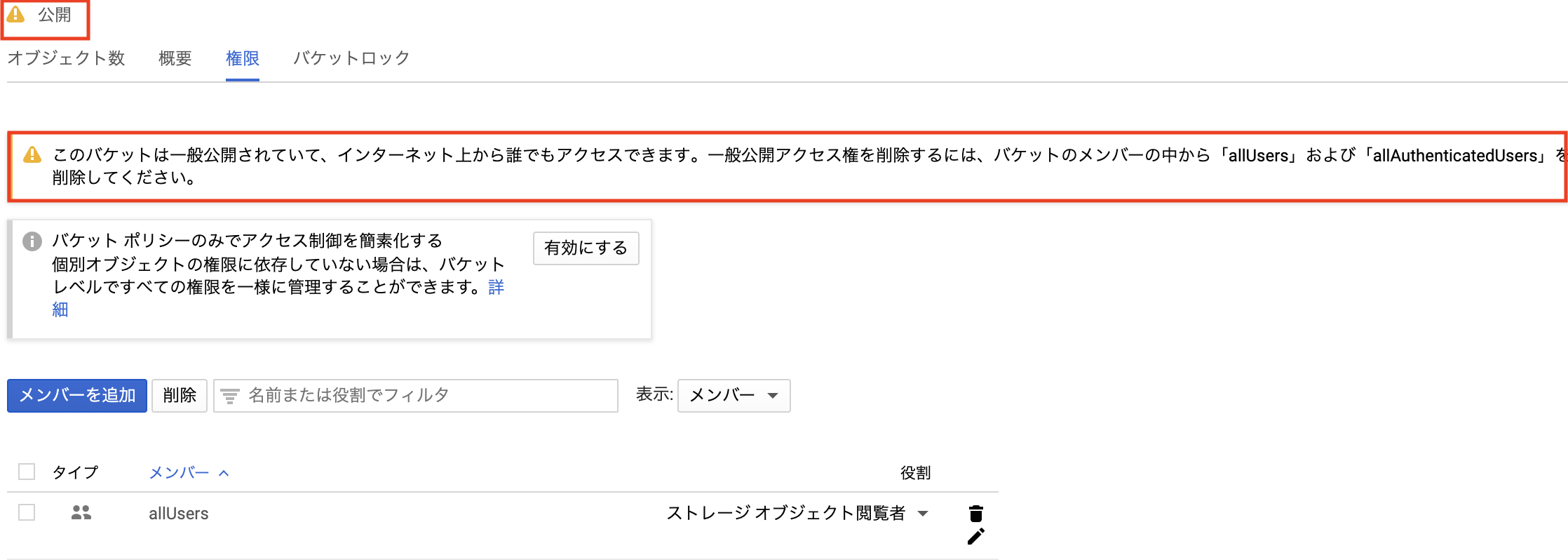
-
公開と表示されていることを確認
- 権限タブからユーザの追加を選択
Cloud Functionsの設定
Cloud Functionsに関数をデプロイします。トリガーには、Cloud Storageのイベントを選択します。
- 各種設定項目を埋める
以下のように、値を入れます。
| # | 設定項目 | 値 |
|---|---|---|
| 1 | 名前 | 任意 |
| 2 | 割り当てられるメモリ | 任意(最大2GB) |
| 3 | トリガー | Cloud Storage |
| 4 | イベントタイプ | ファイナライズ/作成 |
| 5 | バケット | [前章で作成したバケット] |
requirements.txtを書く
関数の実行に必要なパッケージとバージョンをrequirements.txtに書いておきます。
|
1 2 3 4 |
# Function dependencies google-cloud-storage == 1.14.0 google-cloud-bigquery == 1.11.2 |
main.pyを書く
あとは、main.pyにデプロイする関数を書くだけです。今回はランタイムとして、Python3.7を利用します。
[YOUR PROJECT ID]および[YOUR DATASET ID]は既存のものを指定します。
関数の入力データとなるdataとcontextの説明は、下記リンクにあります。

また、Google Cloud Client Library for Pythonのリファレンスはこちらです。

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
from google.cloud import storage, bigquery from datetime import datetime def load_data(data, context): client = bigquery.Client() # 'data' reference is here: # https://cloud.google.com/storage/docs/json_api/v1/objects?hl=ja ################################ # TO DO: Set [YOUR PROJECT ID] # ################################ project_id = '[YOUR PROJECT ID]' ################################ # TO DO: Set [YOUR DATASET ID] # ################################ dataset_id = '[YOUR DATASET ID]' bucket_name = data['bucket'] file_name = data['name'] file_ext = file_name.split('.')[-1] if file_ext == 'csv': uri = 'gs://' + bucket_name + '/' + file_name file_ext = file_name.split('.')[-1] suffix = datetime.now().strftime("_%Y%m%d%H%M%S") table_id = 'tweets' + suffix # Job Configuration dataset_ref = client.dataset(dataset_id) job_config = bigquery.LoadJobConfig(autodetect=True) job_config.skip_leading_rows = 1 job_config.source_format = bigquery.SourceFormat.CSV # Job Request load_job = client.load_table_from_uri( uri, dataset_ref.table(table_id), job_config=job_config ) print('Started job {}'.format(load_job.job_id)) load_job.result() # Waits for table load to complete. print('Job finished.') destination_table = client.get_table(dataset_ref.table(table_id)) print('Loaded {} rows.'.format(destination_table.num_rows)) else: print('Nothing To Do') |
BigQueryの設定
main.pyの変数に定義した名前のデータセットを作っておきます。
他は特にやることはありません。
4. 最後に
今回書いた関数は、GitHubにあげています。あわせてご覧ください。
今後は、BigQueryに読み込んだデータを、GCPの他のサービスと連携させていきたいと思います。
追記:続きはこちら。
以上.

コメント
[…] こちらの記事を参考にさせていただきました。https://nishipy.com/archives/765 […]