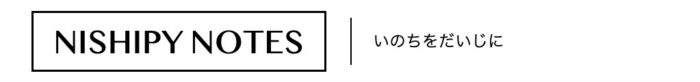
はじめに

Prometheusとは
概要
公式ドキュメントでは、以下のように説明されています。簡単に言うと、オープンソースの監視監視ツールであり、CNCFがホストするプロジェクトです。
同じくCNCFのプロジェクトであるKubernetesのクラスタ監視のツールとして、ここ数年よく耳にします。
Prometheus is an open-source systems monitoring and alerting toolkit originally built at SoundCloud. Since its inception in 2012, many companies and organizations have adopted Prometheus, and the project has a very active developer and user community. It is now a standalone open source project and maintained independently of any company. To emphasize this, and to clarify the project’s governance structure, Prometheus joined the Cloud Native Computing Foundation in 2016 as the second hosted project, after Kubernetes.

全体のアーキテクチャ図も、公式ドキュメントのものがわかりやすいです。
また、関連書籍はそんなに多くありませんが、最近発売された↓の本はとてもわかりやすいです。この記事も、こちらを参考に書いています。
Alert Manager
Alert Managerは、監視対象に異常が発生した際にPrometheusからアラートを受け取り、通知を行います。今回のSlackチャンネルへの通知の他に、メール通知などのも対応しているようです。

Exporter
各監視対象はexporterと呼ばれるエージェントを仕込むことで、メトリクスを公開するエンドポイントとなります。Prometheusは、そのエンドポイントからリクエストを送り、収集されたメトリクスをPullします。Exporterにはいろいろな種類があります。

中でもNode-exporterは、よく使われるようです。これは、監視対象のHWやOSに関するメトリクスを公開するためのエージェントです。
やりたいこと
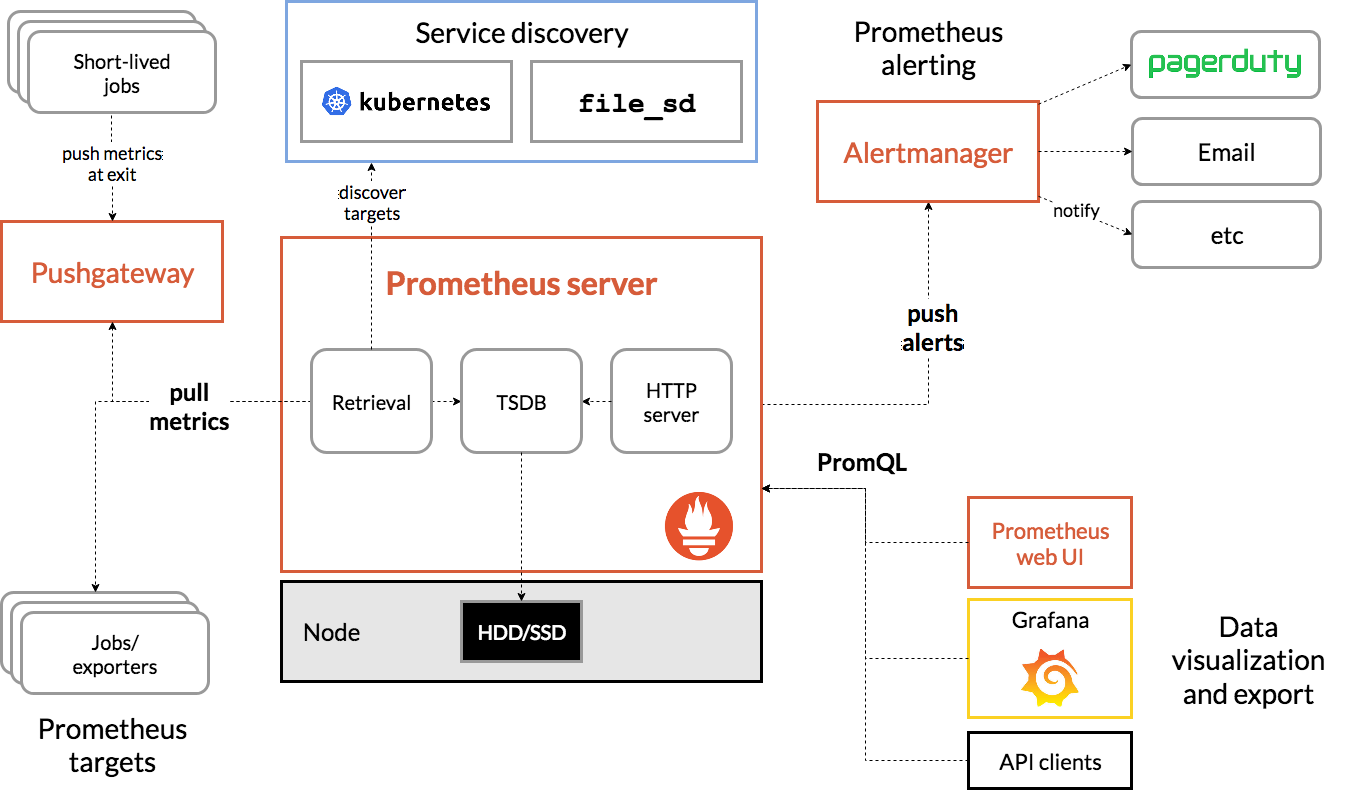
ざっくり書くと、以下のようなことをやってみます。すべてのMacbook上で行います。
- 簡易Webサーバを構築
- 監視用コンテナをデプロイし、下記の監視開始
- Webサーバ
- Node Exporter
- Prometheusにアクセス
- Webサーバを意図的に落とす
- Prometheusが異常を感知し、Slackにアラートを通知
それでは、やってみます。
デモ
1. 簡易Webサーバを構築
前章で紹介した本の原著者であるBrian Brazilさんの↓のGitHubリポジトリから引用します。このコードを実行すると、localhostの8000番ポートでWebサーバが立ち上がります
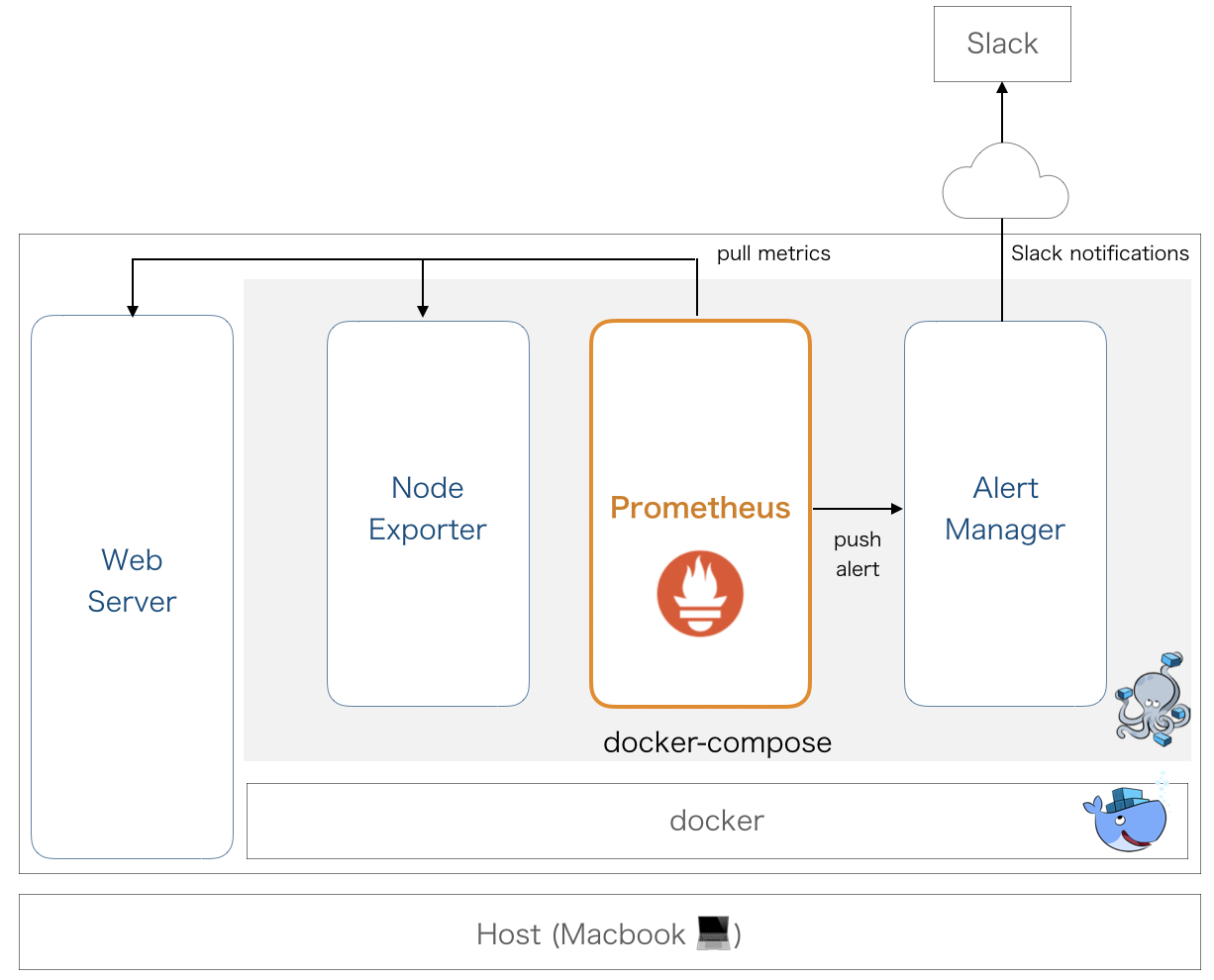
2. 監視用コンテナをデプロイ
以下のdocker-composeファイルから、デプロイします。
|
1 2 |
$ docker-compose up -d |
それぞれのコンテナを、簡単に説明します。
Prometheusコンテナ
prometheus.yamlに設定を書いています。
Alert ManagerやNode Exporter、Webサーバをtargetsに指定する際は注意が必要です。
今回PrometheusはDockerコンテナで構築するので、localhostはPrometeusコンテナ自身を指すため、他のコンテナやWebサーバに通信できません。[[YOUR PRIVATE IP]]としているところに、ホストとなるPCのプライベートIPアドレスに設定することでうまく動作します。コンテナたちをKubernetes Podにまとめると、localhostと書いても通信できると思います。
また、アラートのルールは、rules.yamlに記載しています。up == 0つまりインスタンスが落ちている状態が20秒続けば、アラートを発火します。
Node Exporterコンテナ
設定ファイルは特にありません。ポートは、9100を指定しています。もしKubernetesで使いたいときは、多分DaemonSetにするんでしょう。
Alert Managerコンテナ
alertmanager.yamlに設定を書いています。[[YOUR SLACK WEBHOOK]]には、SlackのWebhook URLを指定してください。また、チャンネルも指定できます。
3. Prometheusにアクセス
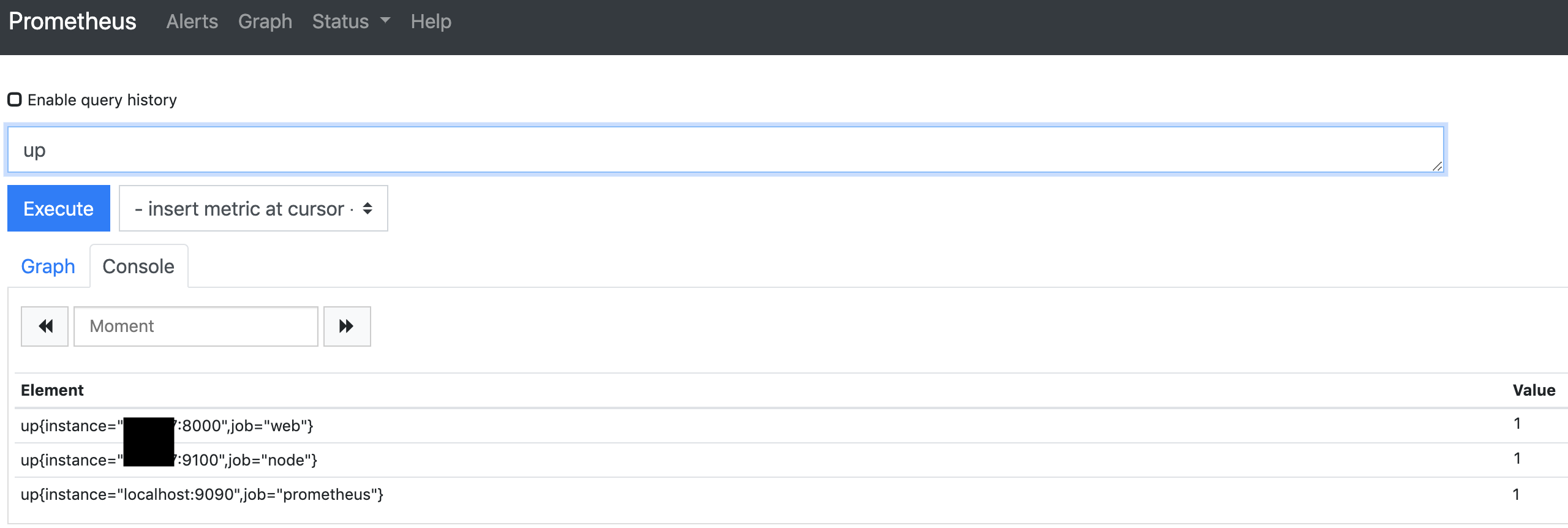
ブラウザからlocalhost:9090にアクセスすると、Prometheusが立ち上がっているのがわかります。
upクエリを実行すると、各監視対象の起動状態が確認できるはずです。この時点では全て正常に起動指定いるはずなので、upの値は1です。
4. Webサーバを意図的に落とす
ステップ1で立ち上げたWebサーバを、[Ctr] + cで落とします。
5. Prometheusが異常を感知し、Slackにアラートを通知
ふたたびPrometheusでクエリupを実行すると、webのupが0になっているはずです。Alert Managerの設定により、この状態が20秒続けば、アラートが発火されます。
しばらくして、Slackの#generalチャンネルを覗いてみると、無事アラートが通知されているのがわかります。

さいごに
Prometheusに入門してみましたが簡単に始められるし、Exporterや通知先も豊富に用意されていて、楽しいですね。
そのうちマネージドサービスとか出るんでしょうか。今後はGrafanaで格好いいダッシュボードを作ったりしたいです。
以上.
コメント