

試しに使ってみたくて、Jリーグのサイトからジョーの得点データを抽出してみることにしました。
1. はじめに
1.1. Webスクレイピングとは
Webスクレイピングの説明は、こんな感じです。
| ウェブスクレイピング(英: Web scraping)とは、ウェブサイトから情報を抽出するコンピュータソフトウェア技術のこと。ウェブ・クローラーあるいはウェブ・スパイダーとも呼ばれる。 通常このようなソフトウェアプログラムは低レベルのHTTPを実装することで、もしくはウェブブラウザを埋め込むことによって、WWWのコンテンツを取得する。[Wikipediaより] |
Webサイトから情報を抽出して、加工することをいうらしいですね。
機械学習の勉強に実データを使いたくてもデータセットとして配布されていないときや、
Webページにデータが乗ってるけど手作業でcsv化するのが面倒なときに使えそうです。
1.2. 動機
Python初心者の私ですが、最近こんな本を読みました。
ライブラリーを使うと、私でもスクレイピングできそうだなあと思い、実際試してみました。
せっかくやるなら、大好きなサッカーに関することの方が楽しそうなので、Jリーグの公式サイトのデータをスクレイピングすることとしました。
当たり前だけど、好きなことと絡めたほうが、勉強も長続きする気がします。
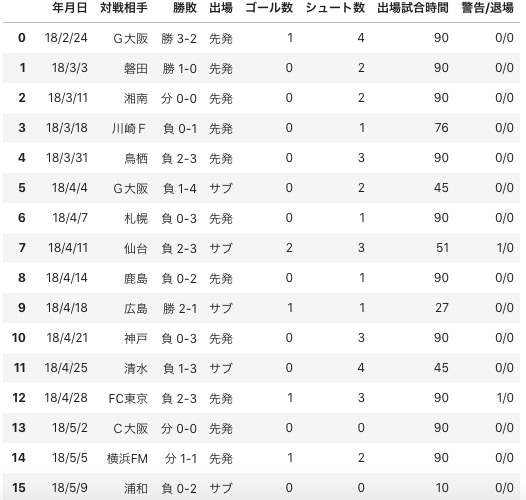
2. ジョーの得点データをスクレイピング
以下で利用するWebサイトのURLを適切に選べば、任意の選手に対して同様のことができます。
(小林悠とか鈴木優磨とか…)
2.1. 概要
- 対象選手: ジョー (名古屋グランパス)
- 対象リーグ: J1 2018年
- 利用するWebサイト: → https://www.jleague.jp/club/nagoya/player/detail/604346/
(バリバリの初心者のため、すでに表形式のデータが公開されているサイトを選ぶこととします) - 利用する言語: Python
2.2. スクレイピングしてみる
(1) Webサイトから情報を取得
利用するWebサイトから、htmlを取得します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import csv import requests import lxml.html from urllib.request import urlopen from bs4 import BeautifulSoup import numpy as np import pandas as pd import matplotlib.pyplot as plt url_Jo = "https://www.jleague.jp/club/nagoya/player/detail/604346/" html = urlopen(url_Jo) # 文字コードをUTF-8とする encoding = html.info().get_content_charset(failobj="utf-8") html = html.read().decode(encoding) |
(2) 必要なデータのみ抽出
取得したhtmlから、必要なデータのみを抽出します。
BeautifulSoupを使うのが良さそうです
|
1 2 3 4 5 6 |
soup = BeautifulSoup(html, 'html.parser') # 今年の成績のみを、dataとして抽出 data = soup.find_all('table', class_='dataTable playerTable')[1] print(data) |

まだタグはついていますが、それっぽいです。
(3) csvに出力
さっきのデータを、csvに出力してみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# thタグの中身を、csvのヘッダーに採用 csv_headers = [] for th in data.find_all('th'): csv_headers.append(th.text) # ヘッダーの数を数えておく(8個) n_headers = len(csv_headers) # tdタグの中身を、csvのデータに採用 csv_contents = [] for td in data.find_all('td'): csv_contents.append(td.text) with open('J1_GoldenBotsRace.csv', 'w', newline='') as f: writer = csv.writer(f) writer.writerow(csv_header) for i in range(0, len(csv_content)): writer.writerow(csv_content[i*n_headers:(i+1)*n_headers]) |
(4) pandasで処理
先ほどのcsvをpandasのDataFrameとして読み込んでみます。
pandasの表示みやすいですね。
|
1 2 3 |
pd_df = pd.read_csv("J1_GoldenBotsRace.csv") pd_df |
今回は、2018年シーズンの累積得点数の推移を、goals_transitionとして格納していきます。
|
1 2 3 4 5 6 7 8 9 |
n_games = len(pd_df) goals_transition = [] for i in range(0, n_games): sum = pd_data['ゴール数'][:(i)].sum() goals_transition.append(sum) # n節終了時点での累積得点数になるように調整します goals_transition = goals_transition[1:].append(sum) |
(5) matplotlibで描画
n節終了時のシーズン累積得点数の推移を描画してみます。
そり立つ壁がありますね…
|
1 2 3 4 5 6 7 8 9 |
setsu = range(1, n_games+1) plt.plot(setsu, goals_transition) plt.ylim(0, max(goals_transition)+1) plt.xlim(1, n_games+1) plt.xlabel("Games") plt.ylabel("Goals") plt.legend(['Jo(Nagoya)'], loc="best") |
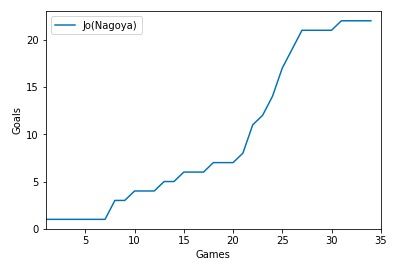
そり立つ壁がありますね。
3. まとめ
3.1. 所感
興味本位でやってみました。所感は以下の通りです。
- 自分で考えながらコードを書くので、本を読んでいるより楽しかった
- ライブラリの使い方を調べながら実装したため、覚えることが多かった
- 20節から25節あたりのジョーさん、半端ない
ちなみに、スクレイピングに関しては、この本がわかりやすかったです。
[amazonjs asin=”4774183679″ locale=”JP” title=”Pythonクローリング&スクレイピング -データ収集・解析のための実践開発ガイド-“]
3.2. 今後やりたいこと
主に2点です。ふんわりしていますが、暖かく見守ってくださいませ。
- 今回のデータで、特長量を整備する練習がしたい
- 今回のデータで特長量エンジニアリングした後、モデルを適応し、何かしたの予測がしたい。
3.3. 注意
Webスクレイピングはをやりすぎると、相手のサーバーやネットワークに過剰な負荷をかけてしまうことがあるので、注意が必要です。

以上


コメント