
1. はじめに
クラス分類のモデルを評価する指標として、混同行列(Confusion Matrix)が重要らしいです。
知ってはいるけど、詳細を忘れがちなので、自分なりにまとめます。とりあえず、2値分類についてメモしていきます。
2. 定義いろいろ
混同行列(Confusion Matrix)
2値分類の場合、混同行列は2×2の行列です。今回は見やすいように表にします。こんな感じです。
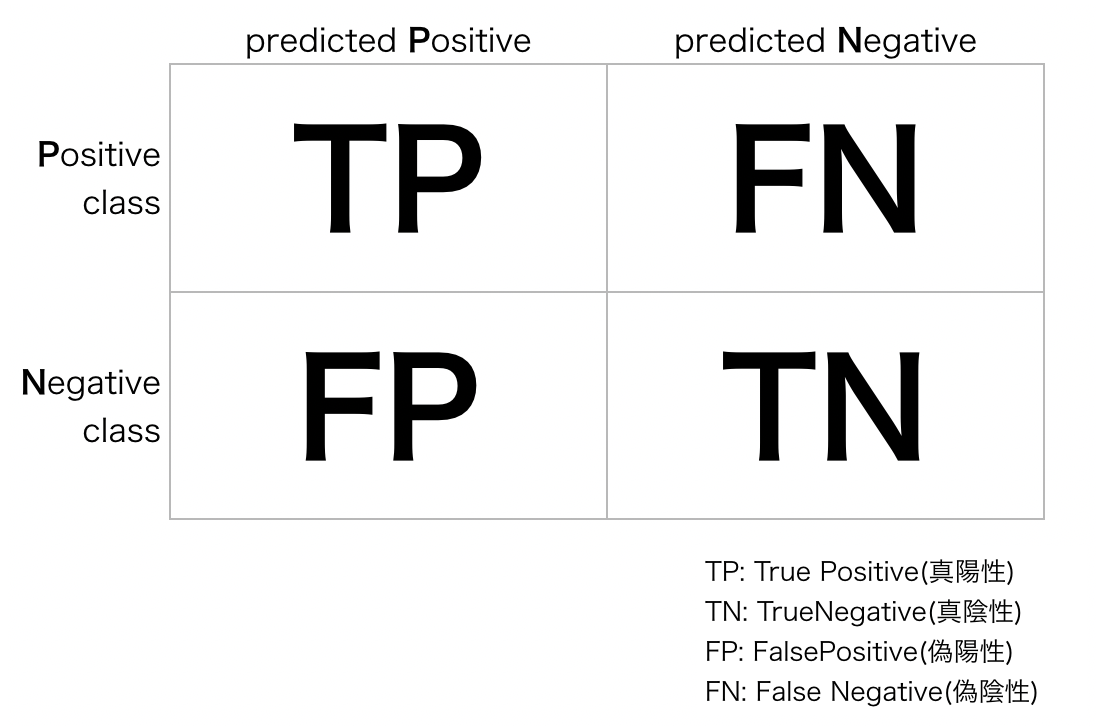
以前の記事(↓)で行ったSmalling/Obama判別を例とします。

(例) 写真がSmallingであるかないかを判断する場合
- Positive: Smallingである
- Negative: Smallingでない
であるから、それぞれの値は以下のように説明できます。
- \(TP\): 正しく、Smallingである判断した数
- \(FP\): 誤って、Smallingである判断した数
- \(TN\): 正しく、Smallingでないと判断した数
- \(FN\): 誤って、Smallingでないと判断した数
精度、適合率、再現率、f-値
混同行列から、以下のような値も導かれますが、これがなかなかややこしい。きっと使ってるうちに覚えるのでしょう。
- 精度: このモデルの精度は、以下の式で書ける
$$\frac{TP + TN}{TP + TN + FP+ FN}$$ -
適合率(precision): 陽性と判断されたものが、実際に陽性であった程度を測定する指標
$$\frac{TP}{TP + FP}$$ -
再現率(recall): 実際に陽性であるもののが、陽性と予測された程度を測定する指標。真陽性率。
$$\frac{TP}{TP + FN}$$ -
f-値: 適合率と再現率の調和平均
$$F = 2 \times \frac{適合率 \times 再現率}{適合率 + 再現率}$$
受信者動作特性(ROC)曲線、AUC
-
ROC曲線: x軸に偽陽性率(FPR)を、y軸に真陽性率(=再現率)をプロットする。
- 偽陽性率: 全ての陰性サンプル数に対する、偽陽性サンプル数の割合
$$\frac{FP}{FP + TN}$$
- 偽陽性率: 全ての陰性サンプル数に対する、偽陽性サンプル数の割合
- AUC: ROCカーブの下の領域の面積。area under the curveの略。1に近いほどよい。
3. scikit-learnによる実装
今回は、お手軽なsklearn.datasetsの乳がんデータセットを使います。
決定木で分類した時の、混同行列などについて、みていきます。データをロードして、予測結果をy_predとしておきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier cancer = load_breast_cancer() X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, stratify=cancer.target, random_state=0) tree = DecisionTreeClassifier(max_depth=4, min_samples_leaf=3) tree.fit(X_train, y_train) y_pred = tree.predict(X_test) |
予測するのは、腫瘍が良性か悪性かです。
|
1 2 |
print(cancer.target_names) |
混同行列(Confusion Matrix)
sklearn.metrics.confusion_matrixを利用します。
|
1 2 3 |
from sklearn.metrics import confusion_matrix print(confusion_matrix(y_test, y_pred)) |
[[48 5]
[ 5 85]]
精度、適合率、再現率、f-値
これも、sklearn.metricsからimportして利用できます。
|
1 2 3 4 5 6 7 |
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score print('精度:{:.3f}'.format(accuracy_score(y_test, y_pred))) print('適合率:{:.3f}'.format(precision_score(y_test, y_pred))) print('再現率:{:.3f}'.format(recall_score(y_test, y_pred))) print('f-1値:{:.3f}'.format(f1_score(y_test, y_pred))) |
精度:0.930
適合率:0.944
再現率:0.944
f-1値:0.944
ROC曲線、AUC
追記予定
4. さいごに
- クラス分類のモデルを評価するために、混同がとても重要らしい
- モデルはだいたい覚えてきたけど、モデルの評価指標を疎かにしがちなので、適宜まとめていきたい
以上

コメント