

1. はじめに
1.1. 背景
詳しくは、前編の記事をご覧ください。
1.2. 今回やりたいこと
前編で用意した画像を用いで、CNN(畳み込みニューラルネットワーク)のモデルを学習させていきます。
学習後のモデルで、問題の画像がオバマなのかスモーリングなのかを判定します。
以下のページが大変参考になりました。
2. 画像の振り分け
用意したデータを3種類に振り分けます。
- 訓練データ
- 検証データ
- テストデータ
2.1. ディレクトリの作成
まずは、画像を振り分けて格納するディレクトリを用意します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import os, shutil def make_mydir(path): if not os.path.isdir(path): os.makedirs(path) base_dir = './obama_and_smalling/' make_mydir(base_dir) train_dir = os.path.join(base_dir, 'train') valid_dir = os.path.join(base_dir, 'valid') test_dir = os.path.join(base_dir, 'test') train_smalling = os.path.join(train_dir, 'smalling') valid_smalling = os.path.join(valid_dir, 'smalling') test_smalling = os.path.join(test_dir, 'smalling') train_obama = os.path.join(train_dir, 'obama') valid_obama = os.path.join(valid_dir, 'obama') test_obama = os.path.join(test_dir, 'obama') dir_list = [train_dir, valid_dir, test_dir, train_smalling, valid_smalling, test_smalling, train_obama, valid_obama, test_obama] for d in dir_list: make_mydir(d) |
2.2. 画像数の再確認
前編を書いた後に再確認した結果、別人の画像を取り除けていませんでした。
用意できた画像の枚数を再度、確認しておきます。
|
1 2 3 4 5 6 7 8 |
org_smalling_dir = './faces/smalling/' org_obama_dir = './faces/obama/' smalling_faces = os.listdir('./faces/smalling/') obama_faces = os.listdir('./faces/obama/') print('Smalling has {} faces '.format(len(smalling_faces))) print('Obama has {} faces '.format(len(obama_faces))) |
出力は、以下の通りでした。
* Smalling has 231 faces
* Obama has 255 faces
2.3. 振り分け
2.2の通り、それぞれの合計枚数が違いますが、せっかく収集したので、全部使いたいです。
訓練データと検証用データは同じ枚数にしたいので、以下のように振り分けてみます。
| data | #Smalling | #Obama |
|---|---|---|
| 訓練データ | 130 | 130 |
| 検証データ | 50 | 50 |
| テストデータ | 51 | 75 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 一応シャッフル import random random.shuffle(smalling_faces) random.shuffle(obama_faces) smalling_train = [smalling_faces[i] for i in range(130)] smalling_valid = [smalling_faces[i] for i in range(130, 180)] smalling_test = [smalling_faces[i] for i in range(180, 231)] obama_train = [obama_faces[i] for i in range(130)] obama_valid = [obama_faces[i] for i in range(130, 180)] obama_test = [obama_faces[i] for i in range(180, 255)] # zip使いたかった list_data = [smalling_train, smalling_valid, smalling_test, obama_train, obama_valid, obama_test] list_src = [org_smalling_dir, org_smalling_dir, org_smalling_dir, org_obama_dir, org_obama_dir, org_obama_dir] list_dest = [train_smalling, valid_smalling, test_smalling, train_obama, valid_obama, test_obama] for data,src,dest in zip(list_data, list_src, list_dest): for d in data: src_file = os.path.join(src, d) dest_file = os.path.join(dest, d) shutil.copyfile(src_file, dest_file) |
ここまではローカルで作業していました。
3. モデルの構築と学習
これ以降は、GPUも使いたいので、すべてGoogle Colab上で作業します。
3.1. データのアップロード
振り分けた画像をzipファイルとして、Google Colab環境にアップロードします。 あらかじめ、zipファイルはGoogle Driveのマイドライブに入れておきます。
以下のようにマイドライブを/conten/driveにマウントして、アップロードしてください。
|
1 2 3 4 5 |
from google.colab import drive # マイドライブをマウント drive.mount('/content/drive') |
また、Google Colabに移ってきたので、ディレクトリ名を入れていた変数を再定義します。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import os base_dir = './obama_and_smalling/' train_dir = os.path.join(base_dir, 'train') valid_dir = os.path.join(base_dir, 'valid') test_dir = os.path.join(base_dir, 'test') train_smalling = os.path.join(train_dir, 'smalling') valid_smalling = os.path.join(valid_dir, 'smalling') test_smalling = os.path.join(test_dir, 'smalling') train_obama = os.path.join(train_dir, 'obama') valid_obama = os.path.join(valid_dir, 'obama') test_obama = os.path.join(test_dir, 'obama') |
3.2. 訓練画像の水増し
訓練画像が少ないと過学習してしまうので、kerasのImageDataGeneratorをつかって水増しを行います。回転させたり、シフトさせたり、ズームしたりして、画像を水増しするようです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
from keras.preprocessing.image import ImageDataGenerator from keras.preprocessing import image import matplotlib.pylab as plt # 水増し用ジェネレータ datagen = ImageDataGenerator( rotation_range=45, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, fill_mode='nearest') |
何枚か、水増しされた画像の例をみてみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# スモーリングの訓練画像リスト smalling_face = [os.path.join(train_smalling, face) for face in os.listdir(train_smalling)] # 100枚目を元にする img_path = smalling_face[99] # 画像を(150, 150, 3) のnumpy arrayに変換 img = image.load_img(img_path, target_size=(150, 150)) x = image.img_to_array(img) # (1, 150, 150, 3)に整形 x = x.reshape((1,) + x.shape) i = 0 fig = plt.figure(figsize=(15, 10)) for batch in datagen.flow(x, batch_size=1): ax = fig.add_subplot(2, 2, i+1) # 2*2= 4枚まで ax.grid(False) imgplot = ax.imshow(image.array_to_img(batch[0])) i += 1 # ジェネレータなので、どこかでbreakする必要がある if i == 4: break plt.show() |

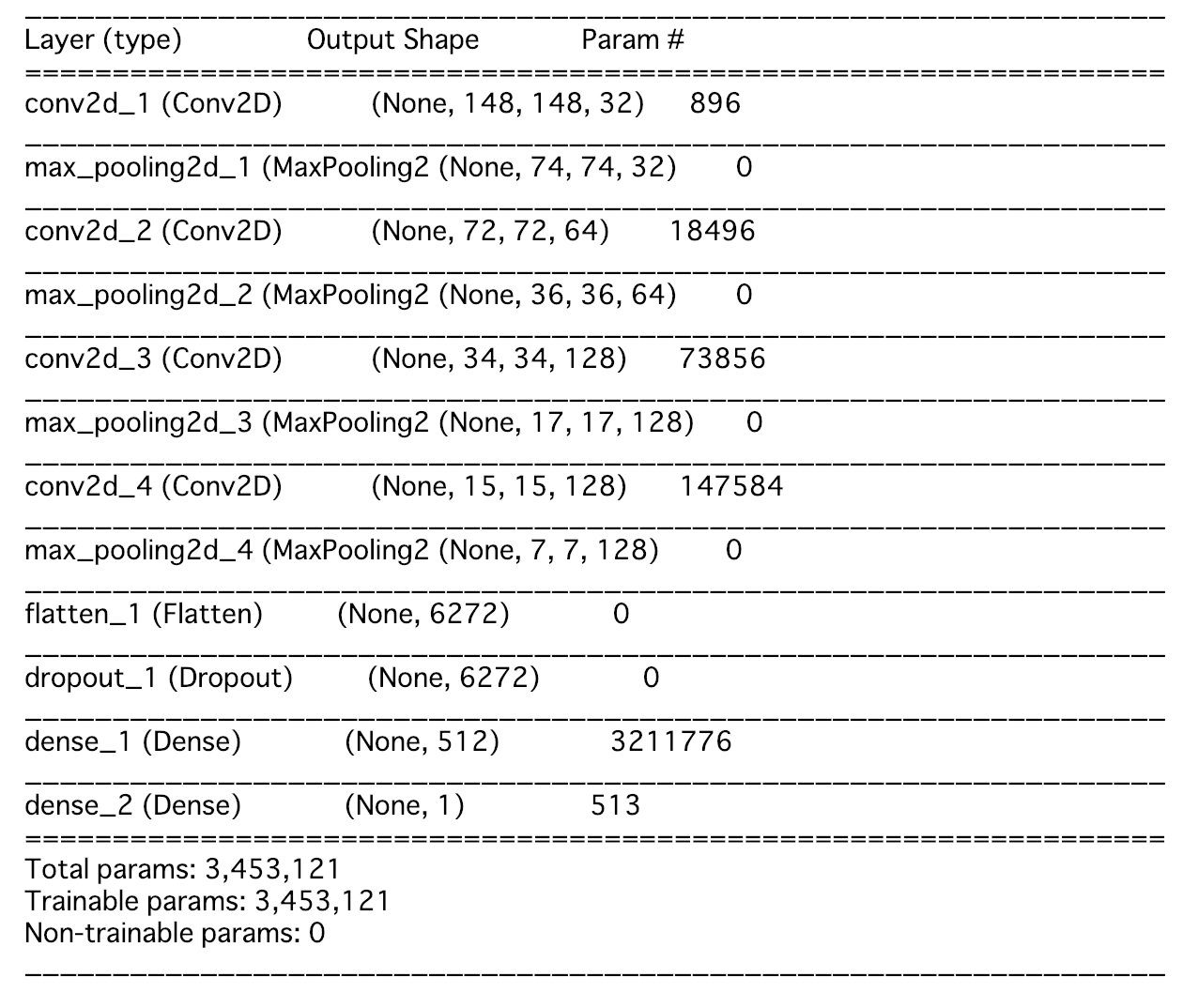
3.3. モデルの構築
今回学習させるCNNを構築します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
from keras import layers, models, optimizers model = models.Sequential() model.add(layers.Conv2D(32, (3, 3), activation='relu',input_shape=(150, 150, 3))) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(128, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(128, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Flatten()) model.add(layers.Dropout(0.5)) # 過学習抑制のために、全結合層の前にDropout層を追加 model.add(layers.Dense(512, activation='relu')) model.add(layers.Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', # 二値に分類するため optimizer=optimizers.RMSprop(lr=1e-4), metrics=['acc']) |
一応サマリをみておきます。
|
1 2 |
model.summary() |
3.4. モデルの学習
CNNを学習させます。500epoch回して、5分くらいで終わりました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
# 訓練データは水増し train_datagen = ImageDataGenerator( rescale=1./255, # 正規化 rotation_range=40, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True,) # 訓練データ以外は水増ししないこと! test_datagen = ImageDataGenerator(rescale=1./255) # 訓練データの画像を読み込み train_generator = train_datagen.flow_from_directory( train_dir, target_size=(150, 150), # 画像サイズを(150, 150)に変換 batch_size=26, # バッチサイズ。慣習として2のべき乗とすることが多いらしいが、、 class_mode='binary') # 二値分類 # 検証データの画像を読み込み validation_generator = test_datagen.flow_from_directory( valid_dir, target_size=(150, 150), batch_size=10, class_mode='binary') # ジェネレータを使ったモデルの学習 history = model.fit_generator( train_generator, steps_per_epoch=10, # 1エポック内でミニバッチを回す回数 epochs=500, # エポック数(100と500で試しています) validation_data=validation_generator, # 検証用ジェネレータを指定 validation_steps=50) |
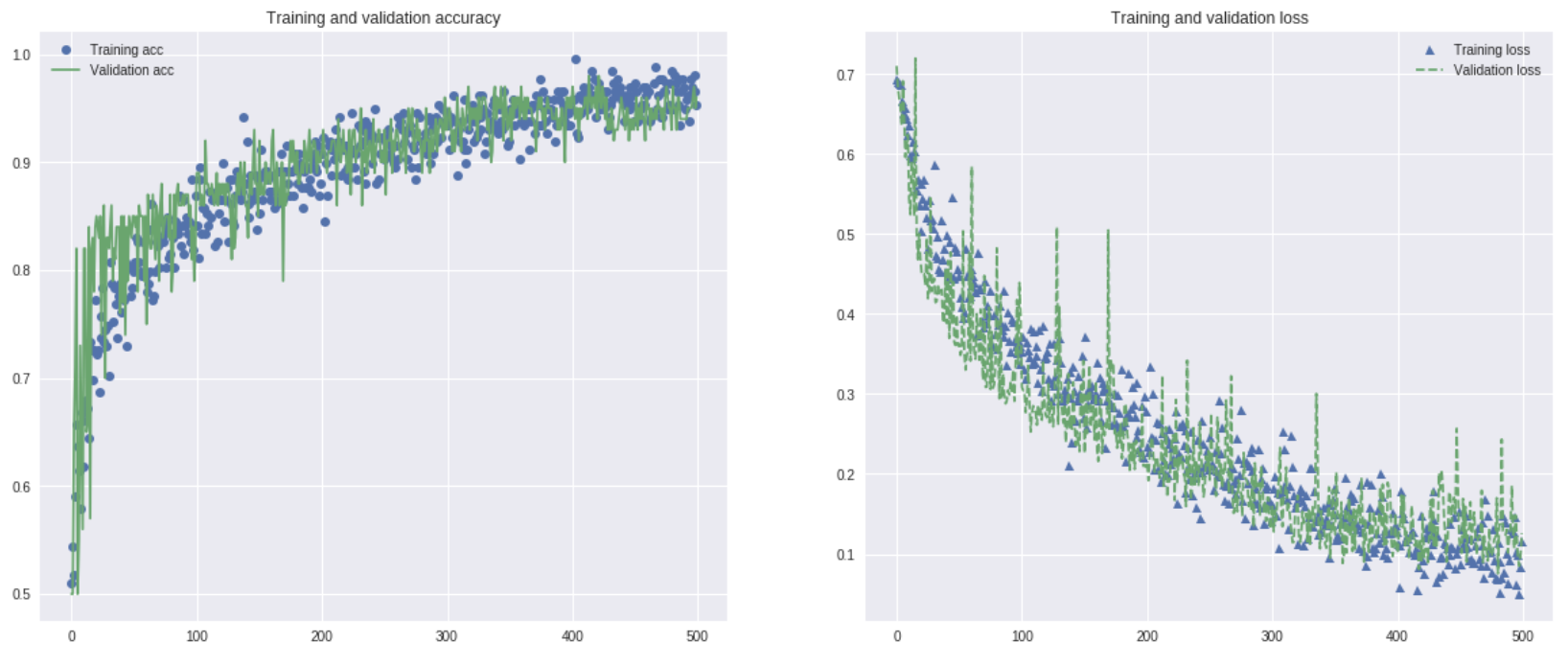
学習の過程はこんな感じ。順調ではないでしょうか。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs = range(len(acc)) plt.figure(figsize=(20,8)) plt.subplot(1,2,1) plt.plot(epochs, acc, 'o', label='Training acc') plt.plot(epochs, val_acc, '-', label='Validation acc') plt.title('Training and validation accuracy') plt.legend() plt.subplot(1,2,2) plt.plot(epochs, loss, '^', label='Training loss') plt.plot(epochs, val_loss, '--', label='Validation loss') plt.title('Training and validation loss') plt.legend() plt.show() |
学習済みのモデルを保存しておきます。
|
1 2 |
model.save('obama_smalling_predictor.h5') |
4. モデルの評価
テストデータを使って、評価していきます。
4.1. テストデータにおける精度
まず、evaluate_generatorをつかって、精度を評価します。
|
1 2 3 4 5 6 7 8 9 |
test_generator = test_datagen.flow_from_directory( test_dir, target_size=(150, 150), batch_size=18, class_mode='binary') test_loss, test_acc = model.evaluate_generator(test_generator, steps=20) print('test acc:', test_acc) |
![]()
4.2. テストデータにおける予測
最後に、今回学習させたモデルを使って、与えられた画像がオバマなのかスモーリングなのかを予測してみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
from PIL import Image import numpy as np def obama_smalling_predictor(image_path): img = Image.open(image_path).convert('RGB') img = img.resize((150, 150)) x = np.array(img, dtype=np.float32) x = x / 255. x = x.reshape((1,) + x.shape) pred = model.predict(x, batch_size=1, verbose=0) score = np.max(pred) pred_label = np.argmax(pred) # 予測値に表示 if(score >= 0.5): print('[Smalling] {:.4%} Sure.'.format(score)) else: print('[Obama] {:.4%} Sure.'.format(1-score)) # 画像の表示 plt.imshow(img) plt.grid(False) sample_smalling = './obama_and_smalling/test/smalling/0022_1.jpg' sample_obama = './obama_and_smalling/test/obama/0011_1.jpg' |
|
1 2 3 |
# テストデータのスモーリング画像から予測 obama_smalling_predictor(image_path=sample_smalling) |
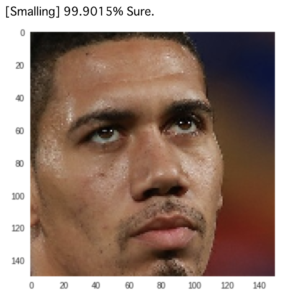
|
1 2 3 |
# テストデータのオバマ画像から予測 obama_smalling_predictor(image_path=sample_obama) |

4.3. 問題の画像を予測!!
マグカップにプリントされてしまった顔写真を予測してみます。
|
1 2 3 |
my_target = './Obama_or_Smalling.jpg' obama_smalling_predictor(image_path=my_target) |

たぶんできた
5. 最後に
5.1. 今回できたこと
- スモーリングとオバマを判別するCNNを作りました
- 人類がスモーリングのマグカップにオバマの顔写真をプリントすることがなくなりました
5.2. これからやりたいこと
- kerasじゃなくて、PyTorchつかいたい
以上

コメント