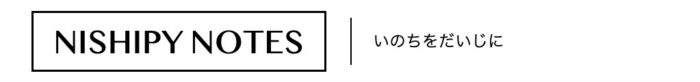
1. やりたいこと

2. 予備知識
KubernetesのWorker Nodeのログを、FluentdによりS3に転送するにあたり、予備知識について少しまとめます。
Fluentd
![]()
ググってみると、オープンソースのデータ収集ソフトウェアと書かれています。「データを収集して転送する」というようなことが実現できるようです。
特に、各サーバのアプリケーションログやコンテナログを収集して転送し、ログの保存や解析を担うサーバに集約するような使い方が多いようです。
また、多くのプラグインが用意されており、データ転送先の選択肢が豊富です。
- Amazon S3
- Google Cloud Storage(GCS)
- Elasticsearch
- CloudWatch Logs
- Stackdriver Logging など
Kubernetes
![]()
オープンソースのコンテナオーケストレーションシステムであるKubernetesは、ここ数年よく耳にするようになりました。私も近頃、仕事で使う機会が増えてきたため勉強しているところです。ちなみに2018年は、Kubernetesのスキルがある人が、米国の転職市場でもっとも有利だったらしい。この流れは、日本にも来るのでしょうか。来てほしい。
日本語の本だと、これがすごく良いです。いつもお世話になっています。
KubernetesのWorkerノードや、その上で動くコンテナログを収集する際は、FluentdのDaemonsetを使うことが推奨されているようですので、今回実装してみます。
ログ収集に関しても、↑の本の16章に記載があり、FluentdからStackdriver Loggingにログを転送する例が解説されています。
同じことをしても面白くないので、この記事ではFluentdからAWSのS3にログを転送する方法を検討します。
3. 下準備
Kubernetes環境
S3を使うということで、私はEKSでKubernetesをデプロイしました。このあたりを参考にして、用意してください。

S3バケット
ログを転送するS3バケットも、あらかじめ用意してください。また、バケットポリシーも適切に設定しておいてください。
S3プラグインのGithubに載っている情報を元に、設定すれば、おそらく問題ないと思います。
例えば、こんなポリシーとか。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:ListBucket" ], "Resource": "arn:aws:s3:::my-s3bucket" }, { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject" ], "Resource": "arn:aws:s3:::my-s3bucket/*" } ] } |
試したいだけなら、バケットを公開するのもありかもしれません。
|
1 2 3 4 5 6 |
"Statement": [{ "Effect": "Allow", "Action": "s3:PutObject", "Resource": ["*"] }] |
アクセスキー
バケットに転送するために、アクセスキーも用意しておきます。こちら、ご参考。

Dockerイメージ
fluentd公式のDockerイメージに、S3プラグインをインストールします。今回は、予めDockerイメージとしてビルドしていますが、Kubernetesのマニフェストでやってもいいと思います。
fluent-plugin-s3をインストール済みのDockerイメージは、Dockerhubに公開しています。

4. やってみる
これだけ下準備ができれば、残りはkubernetesのマニフェストファイルを書くだけです。
ConfigMap
まずは、fluentdの設定ファイルfluent.confを、KubernetesのConfigMapとして定義します。今回は/var/log/messagesを、fluentdによりtailして、S3に転送します。<match td.messages>...</match>内の、aws_key_idやs3_bucketなどの値は、下準備で用意したものに置き換えてください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
apiVersion: v1 kind: ConfigMap metadata: name: fluentd-config labels: k8s-app: fluentd-s3 data: fluent.conf: | <source> @type tail path /var/log/messages tag td.messages pos_file /var/log/td-agent/messages.pos format syslog </source> <match td.messages> @type s3 aws_key_id [[YOUR KEY]] aws_sec_key [[YOUR SECRET KEY]] s3_bucket [[YOUR BUCKET NAME]] s3_region [[YOUR REGION]] path "#{ENV['NODE_NAME']}/messages" time_slice_format %Y%m%d/%H%M </match> |
ちなみに<match td.messages>...</match>のpathは、Worker Nodeのホスト名によりスライスされるように設定しています。Worker Nodeのホスト名は、後述のDaemonsetのマニフェストファイルで、環境変数NODE_NAMEに渡します。
DaemonSet
次に、DaemonSetの定義を行います。下準備に記載したDockerイメージをpullして、設定していきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
apiVersion: apps/v1 kind: DaemonSet metadata: name: fluentd-s3-ds spec: selector: matchLabels: k8s-app: fluentd-s3 template: metadata: labels: k8s-app: fluentd-s3 spec: # https://github.com/fluent/fluentd-kubernetes-daemonset/issues/90 initContainers: - name: copy-fluentd-config image: busybox command: ['sh', '-c', 'cp /config-volume/..data/* /fluentd/etc'] volumeMounts: - name: config-volume mountPath: /config-volume - name: fluentdconf mountPath: /fluentd/etc containers: - name: fluentd-s3 image: nishipy/fluentd-s3:latest env: - name: NODE_NAME valueFrom: fieldRef: fieldPath: spec.nodeName resources: limits: cpu: 100m memory: 200Mi volumeMounts: - name: config-volume mountPath: /config-volume - name: fluentdconf mountPath: /fluentd/etc - name: varlog mountPath: /var/log volumes: - name: config-volume configMap: name: fluentd-config - name: fluentdconf emptyDir: {} - name: varlog hostPath: path: /var/log |
マニフェストファイルの適用
マニフェストファイルを、kubectl applyで適用します。うまくいかない時は、kubectl log [Pod Name]でデバッグしましょう。
S3バケットを見てみる
最後にAWSコンソールで、S3バケットを見てみます。しばらくすると、S3にログが転送されてくるのがわかります。<match td.messages>...</match>のpathで設定したように、各Worker Nodeのホスト名が含まれた形でスライスできています。
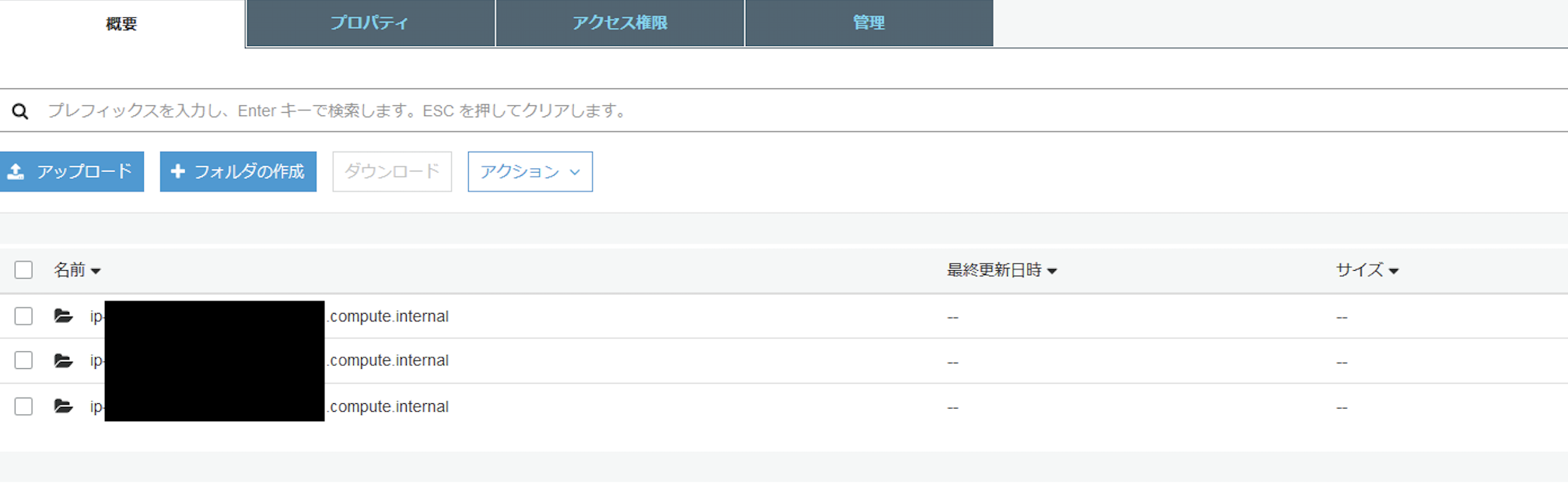
できた!
5. 最後に
DaemonSetを初めて知った時は、「これいつ使うん?」と思っていました。あの頃の自分をしばきたい。Fluentdと組み合わせると、すごく便利そうですね。今回はログの保管を目的としてS3を使いましたが、Elasticsearch+Kibanaに転送して、ログの可視化を行うのも面白そうです。
Kubernetes楽しいので、いろいろやってみて、また記事にします。最後まで読んでいただきありがとうございます。
以上.
コメント