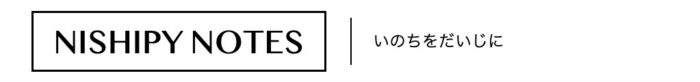


Prometheusとは
概要
公式ドキュメントでは、以下のように説明されています。簡単に言うと、オープンソースの監視ツールであり、CNCFがホストするプロジェクトです。
同じくCNCFのプロジェクトであるKubernetesクラスタの監視のツールとして、よく耳にします。
Prometheus is an open-source systems monitoring and alerting toolkit originally built at SoundCloud. Since its inception in 2012, many companies and organizations have adopted Prometheus, and the project has a very active developer and user community. It is now a standalone open source project and maintained independently of any company. To emphasize this, and to clarify the project’s governance structure, Prometheus joined the Cloud Native Computing Foundation in 2016 as the second hosted project, after Kubernetes.

全体のアーキテクチャ図も、公式ドキュメントのものがわかりやすいです。
また、関連書籍はそんなに多くありませんが、最近発売された↓の本はとてもわかりやすいです。
Prometheus Meetup Tokyo #3 に行ってきた
タイムテーブルは、こちらです。(敬称略)

| 時間 | 内容 | スピーカー |
|---|---|---|
| 18:30~19:00 | 受付開始 (19:30まで) | – |
| 19:00~19:05 | オープニング、会場説明等 (5min) | – |
| 19:05~19:35 | Remote Write API と Thanos を活用したメトリクス永続化 (仮) (30min) | Moto Ishizawa (@summerwind), Z Lab Corporation |
| 19:35~20:05 | Victoria Metricsで作りあげる大規模・超負荷システムモニタリング基盤 (30min) | 入江 順也 (GitHub: inletorder), 株式会社コロプラ |
| 20:05~20:35 | 次世代のログ基盤 Grafana Lokiを始めよう!(30min) | 仲亀 拓馬(@kameneko1004, さくらインターネット 株式会社), 上村 真也(@uesyn, Z Lab Corporation) |
| 20:35~21:05 | 懇親タイム | – |
| 21:05-21:10 | LT 大会 | – |
Remote Write API と Thanos を活用したメトリクス永続化
ゴール
- 180日を超える長期間のメトリクスを参照したい
- Prometheusの収集したメトリクスをすべて外部のオブジェクトストレージ(S3など)に保管し、管理者がいつでも参照できるようにしたい
- 各クラスタにいるPrometheusのRAM消費量を最小限にしたい
実装案1 Cortexを使う
- 構成が複雑
- オブジェクトストレージと連携できないので、だめ
実装案2 独自アダプターを開発する
- オブジェクトストレージと繋ぐだけのアダプターを開発
- Remote Read/Write APIを利用
- メトリクス参照時には、RAMを十分に用意する必要あり

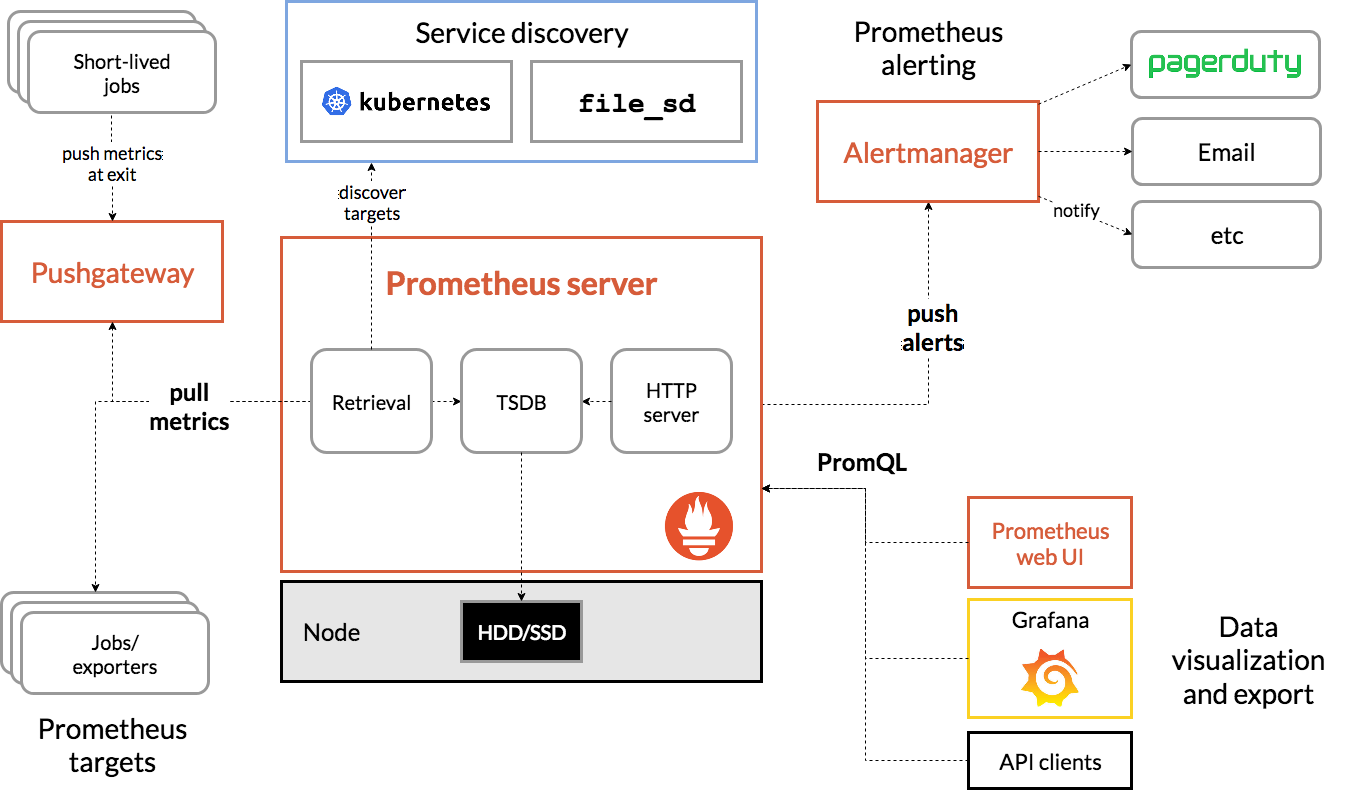
実装案3 Thanosを使う
- CNCFのsandboxプロジェクトらしい
- アーキテクチャは以下を参照のこと(Githubから引用)
引用元:
https://github.com/thanos-io/thanos

- Thanos Recieve、Thanos Store、Thanos Queryなどさまざまなコンポーネントがある
- Thanos Recieve、でメトリクスをオブジェクトストレージに保存
- Thanos Storeで、オブジェクトストレージに保管されたメトリクスにアクセスするAPIを提供
- Thanos Queryで、Prometheus互換のUIからPromQLを用いてメトリクスを集計
今後の課題
- Prometheusから受信するメトリクスが多くなると、、
- 複数メトリクスの混在を防ぐ仕組み
- Thanos Receiveのパフォーマンス
- Thanos Receiveの冗長化
質疑応答
- 検証された環境で、1クラスタあたりの規模は?
- 5〜10ノードくらい
Victoria Metricsで作りあげる大規模・超負荷システムモニタリング基盤
前提と背景
- ドラゴンクエストウォークの環境で蓄積されたメトリクス数: 1500億
- Pod数は1万+
- 今までの基盤
- 各ゲームごとに、各k8sクラスタがある
- そして各クラスタに1つPrometheusがある
- 最大1500ポッドくらい
- ドラゴンクエストウォーク開発において負荷テストを行ったところ、想定の1/4の負荷でPrometheusが死んでいった。。。
- メモリ割り当てを増やすも、OOMKillされる
サードパーティ製ストレージの利用検討
- Thanos検証
- Thanos Sidecarを経由して、Prometheusにクエリ発行
- Remote Read APIの問題により、Prometheusのメモリに負荷がかかる(Prometheusの問題。現在は解消)
- 結果、OOMKilled
- その他、M3DBやCortexも検討したがボツ
VictoriaMetricsの導入

- アーキテクチャは、以下参照。(引用元: https://medium.com/faun/comparing-thanos-to-victoriametrics-cluster-b193bea1683)
引用元:
https://medium.com/faun/comparing-thanos-to-victoriametrics-cluster-b193bea1683
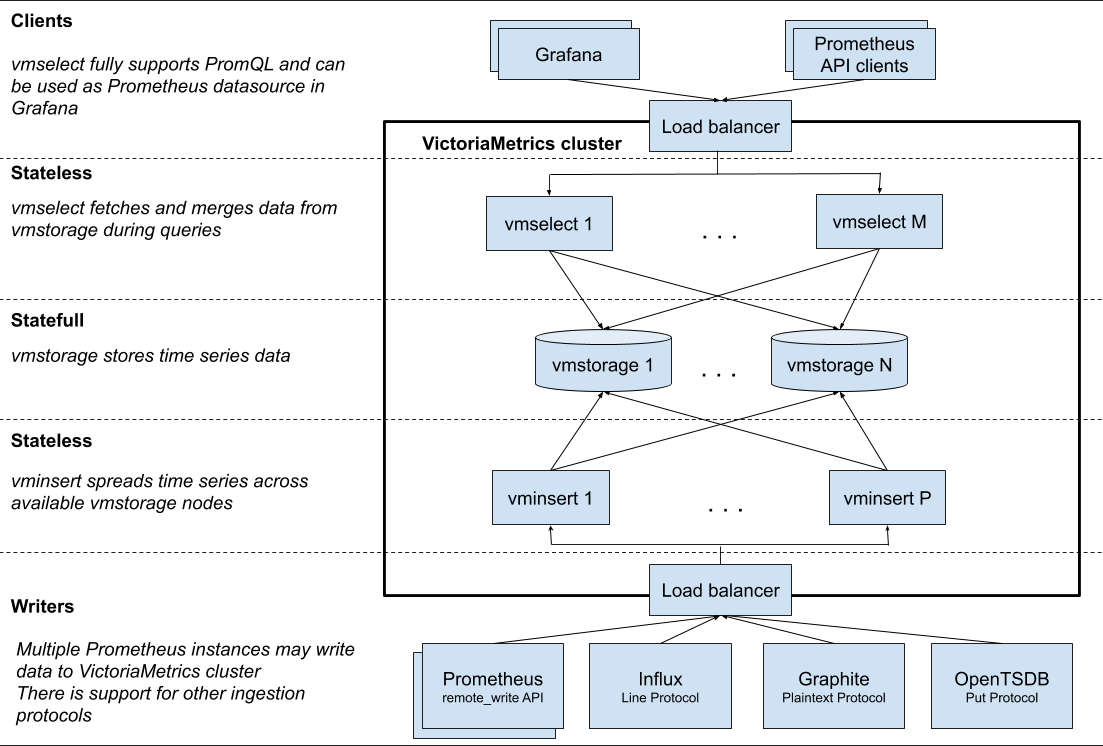
- GrafanaからPrometheusへ直接アクセスしない
- PrometheusはScrape専用で、GrafanaからのクエリはVictoriaMetricsがうける
モニタリング構成・動作検証
- シングルクラスタ構成で、8000Pod以上の環境で問題なく動作
- マルチクラスタ構成で、合計10000Pod以上の環境でも大きな問題なし
今後の課題
- VMStorageのScale-in負荷
- Alert機能はなし
- 現状では、各クラスタのPrometheusにアラート設定
- WebUIがない
- デバッグがしづらいので、デバッグの際はPrometheusにクエリを発行している
質疑応答
- データのレプリカや、ローリングアップデートはできるか?
- 現状できない
- データの永続化はされている?
- PV使ってる
- リテンションは?
- 2年間
- スクレイプのインターバルは?
- 1分間
次世代のログ基盤 Grafana Lokiを始めよう!
Grafana Loki
- Like Prometheus, but for logs
- マルチテナント対応
- ほぼCortexのようなアーキテクチャ
https://github.com/grafana/loki/blob/master/docs/architecture.mdgithub.com - Promtailで、Lokiにログを送る。この時ラベルも付与
- Grafanaと連携できる
- Log Panelをダッシュボードに配置できる
- 動的なアノテーション付与ができる
- (参考動画見つけました)

Promtail
- Fluentdみたいなエージェント
- Kubernetes以外やコンテナ以外でも使える
ログの収集
- promtail.yamlでいろいろ設定する必要あり
- server
- position
- clients
- scrape_configs
- static_configの場合は、Scrapeするログのパスを書く
- ServiceDiscoveryの場合は、Podなどを指定し、relabel_configでlabelを指定しフィルタリング
- などなど
ログからアラートを生成
- pipeline_stagesを使用し、メトリクスを定義
- 正規表現やラベルなどでPromtailのメトリクスを定義
- 正規表現は辛いので、ログはjsonで書くべき!
- PrometheusからScrape
- あとは、いつも通りアラートを仕込む
質疑応答
- Promtailは、Kubernetesしかサポートしていない?
- journalもできるはず
- サービスディスカバリは、Kubernetesくらい
以上.


コメント