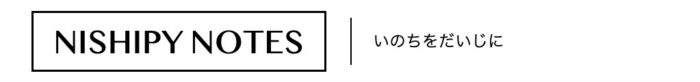

1. はじめに
前回やったこと
↓の記事で、私(@iamnishipy)の全てのツイートを取得し、いいねが多いツイートの傾向について簡単に考察しました。
結果として、画像つきのツイートはいいねが多い傾向にあることがわかりました。私の写真のセンスがいいだけかも知れないので、参考程度にご覧ください。
今回やること
だいたい以下のようなことを行います。
- 自分の全ツイート取得
- 各ツイートの名詞と関連する情報の取得
- ツイートに出現した名詞
- 名詞ごとの出現回数
- 名詞ごとに獲得したいいね数
- いいねに貢献する名詞を分析
2. 自分の全ツイート取得
まず、自分の全ツイートを取得します。Twitter APIを利用した取得方法については、↓の記事を参照してください。
Twitterアカウント固有の認証情報を使うため、Google Colab等のクラウド上ではなく、ローカルで実行するのが良いでしょう。

今回は、ツイート内容を取得する際、URLが含まれないようにしています。URLが上手く分かち書きできず、名詞を抽出する際に邪魔だから。
コードは以下のようにしています。↑の記事と同様に、認証情報は別ファイルに変数として保存してあります。
全ツイートの情報は、csvファイルとして取得します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
import os, sys import tweepy import twitter_api # 認証情報を、別ファイルから取得 key = twitter_api.CONSUMER_KEY key_secret = twitter_api.CONSUMER_SECRET_KEY token = twitter_api.ACCESS_TOKEN token_secret = twitter_api.ACCESS_TOKEN_SECRET def alltweets_to_csv_2(api): import csv import re # 全ツイートを入れる空のリストを用意 all_tweets = [] # 直近の200ツイート分を取得しておく latest_tweets = api.user_timeline(count=200) all_tweets.extend(latest_tweets) # 取得するツイートがなくなるまで続ける while len(latest_tweets)>0: latest_tweets = api.user_timeline(count=200, max_id=all_tweets[-1].id-1) all_tweets.extend(latest_tweets) with open('all_tweets_2.csv', 'w', newline='') as f: writer = csv.writer(f) writer.writerow(['tweet_text', '#characters', '#favorited', '#retweeted', 'hasImage', 'hasBlogLink', 'hasBreak']) for tweet in all_tweets: if (tweet.text.startswith('RT')) or (tweet.text.startswith('@')): continue # RTとリプライはスキップ else: has_image = 0 # 画像付きのツイートか has_bloglink = 0 # ブログへのリンク付きのツイートか tweet_characters = tweet.text # ツイートの文字列 has_break = 0 # 改行があるか if 'media' in tweet.entities: has_image = 1 if len(tweet.entities['urls']) > 0: # urlは、文字数としてカウントしない tweet_characters = tweet_characters.strip(tweet.entities['urls'][0]['url']).strip() if 'nishipy.com' in tweet.entities['urls'][0]['display_url']: has_bloglink = 1 if '\n' in tweet_characters: has_break = 1 tweet_characters = re.sub('\n', '', re.sub('http.*', '', tweet.text)) writer.writerow([tweet_characters, len(tweet_characters), tweet.favorite_count, tweet.retweet_count, has_image, has_bloglink, has_break]) return all_tweets api = auth_twitter_api(key=key, key_secret=key_secret, token=token, token_secret=token_secret) alltweets_to_csv_2(api) |
全ツイートをまとめたcsvファイルを、Google Colabに移して、pandas.DataFrame
|
1 2 3 4 |
import pandas as pd df = pd.read_csv('all_tweets_2.csv') df.head(10) |
3. 各ツイートの名詞と関連する情報の取得
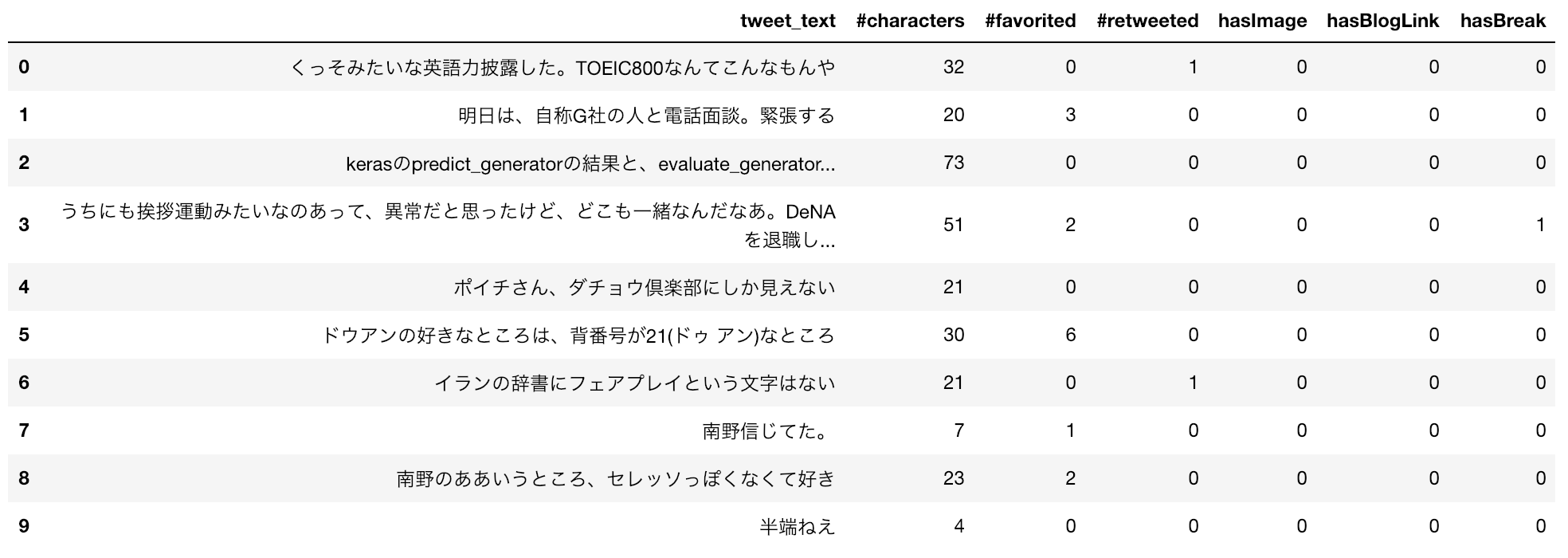
以下の情報を、pandas.DataFrameとして取得します。
- ツイートに出現した名詞
- 名詞ごとの出現回数
- 名詞ごとに獲得したいいね数
ここで「名詞ごとに獲得したいいね数」は、その名詞が含まれたツイートが獲得したいいね数を合計した値とします。
例えば、こんな2つのツイートがあったとき
| # | ツイート | いいね数 |
|---|---|---|
| 1 | リンゴとミカンがおいしい | 10 |
| 2 | やっぱりリンゴが好きです。ブドウも。 | 20 |
→ 「名詞ごとに獲得したいいね数」は、以下のように定めます。
| # | 名詞 | いいね数 | 備考 |
|---|---|---|---|
| 1 | リンゴ | 30 | ツイート#1にもツイート#2にも出現(10+20) |
| 2 | ミカン | 10 | ツイート#1にのみ出現 |
| 3 | ブドウ | 20 | ツイート#2にのみ出現 |
集計するためのコードは、こんな感じにしました。もっとうまい方法が知っている方がいれば、ご教示下さい。
出力結果はこんな感じです。MeCabによると2288個の名詞が出てきたらしいです。
MeCabの使い方は、こちらをご参照ください。

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import re noun_df=pd.DataFrame(columns=['noun', 'appearances', 'favorites']) for i in range(len(df)): tagger = MeCab.Tagger() tagger.parse('') favorites = df['#favorited'][i] node = tagger.parseToNode(str(df.tweet_text[i])) while node: if node.feature.split(',')[0] == '名詞': #print(node.surface, noun_df[noun_df.noun == node.surface]['noun'].count()) if noun_df[noun_df.noun == node.surface]['noun'].count()==0: noun_df.loc[len(noun_df)] = [node.surface, 0, 0] noun_df.loc[noun_df.noun==node.surface, 'appearances'] += 1 noun_df.loc[noun_df.noun==node.surface, 'favorites'] += favorites node = node.next print(noun_df.shape) noun_df.head(10) |
(2288, 3)
4. いいねに貢献する名詞を分析
集計結果を元に、簡単に考察していきます。
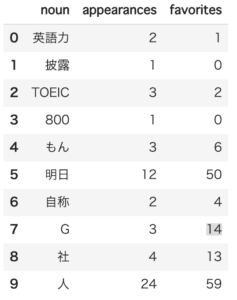
いいね数と出現回数の関係
名詞ごとに出現回数と、獲得したいいね数を描画してみます。
- 全てプロットしてみます。annotateで、重要そうな点には、ラベルを表示します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import numpy as np import matplotlib.pyplot as plt plt.rcParams['font.size'] = 4 plt.rcParams['xtick.labelsize'] = 10 plt.rcParams['ytick.labelsize'] = 10 for i in range(noun_df.shape[0]): x = noun_df.appearances[i] y = noun_df.favorites[i] n = noun_df.noun[i] plt.plot(x, y,'o') if x >= 15 or y >= 30: plt.annotate(n, xy=(x, y)) plt.title('自分がツイートした名詞について', fontsize=8) plt.xlabel('出現回数', fontsize=10) plt.ylabel('いいね数', fontsize=10) plt.savefig("figure.png",format = 'png', dpi=300) plt.show() |
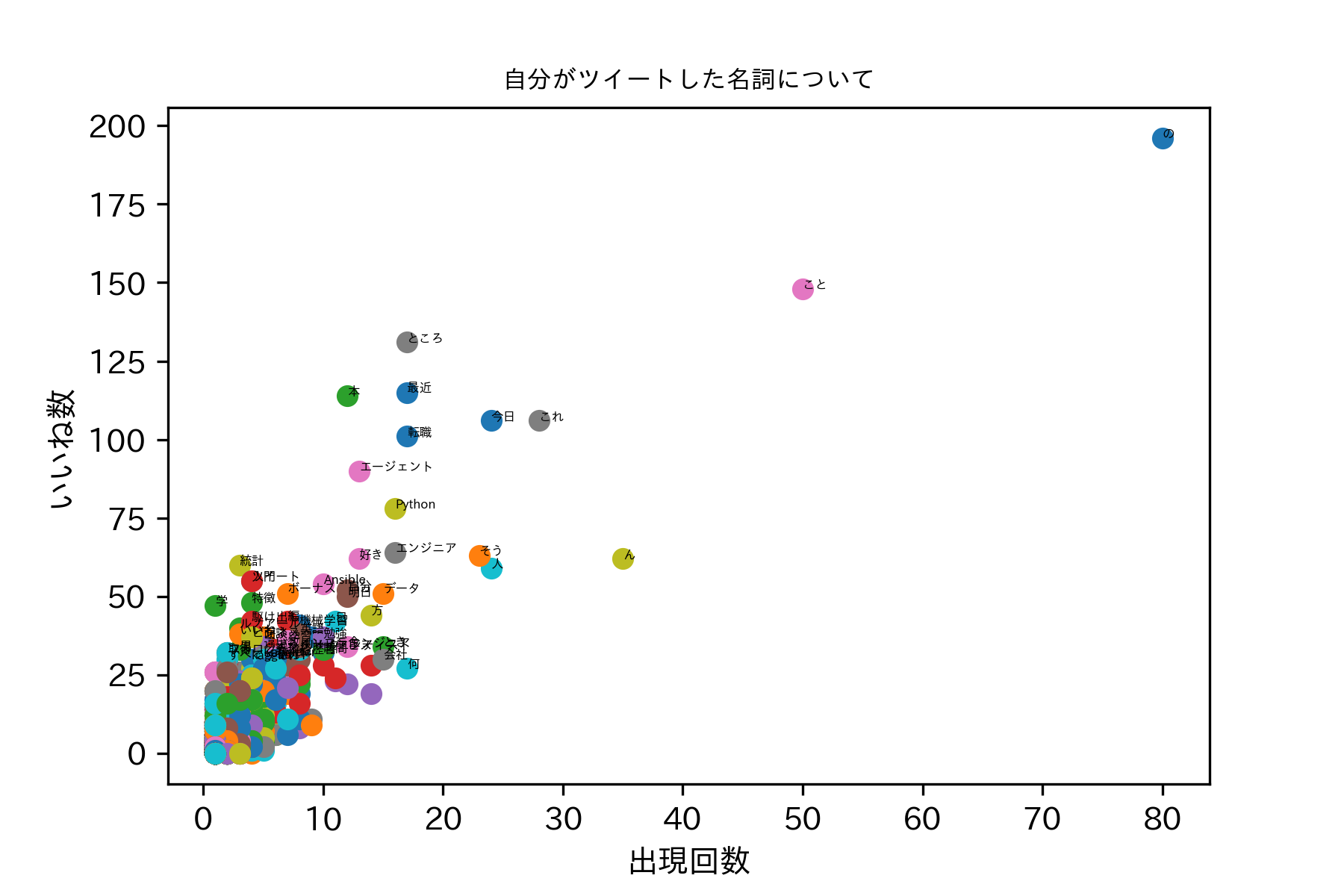
パッとみた感じ
私のフォロワーの方々は、以下のようなツイートを比較的「いいね」と思う気がする。
- 本の話
- 最近の話
- 転職の話
- 転職エージェントの話
- Pythonの話
- 統計の話
- Ansibleの話
- 特徴量の話
- 〇〇学の話
5. さいごに
今後やりたいこと
- word2vec実装
- WordCloud試す
- いいね数予測モデル構築
以上


コメント