
本ブログ用に作ったTwitterアカウントのフォロワーが1000人を超えました!
良い節目ですので、自分の今までのツイートをスクレイピングします。
そして、”いいね”数が多いツイートの傾向について、見ていきます。
良い節目ですので、自分の今までのツイートをスクレイピングします。
そして、”いいね”数が多いツイートの傾向について、見ていきます。
1. はじめに
1.1. 今回やりたいこと
今回やりたいことは、次の通りです。
- TwitterのAPIを用いて、自分(@iamnishipy)の全ツイートを取得する
- “いいね”されやすいツイートについて、考察する
- 文字数の多いツイートは、”いいね”が多い?
- 画像付きのツイートは、”いいね”が多い?
- ブログへのリンク付きのツイートは、”いいね”が多い?
1.2. Twitter APIとは?
前回にまとめましたので、ご覧ください。

[初心者向け]TwitterのAPIを使う方法!開発者アカウント申請と認証情報取得
NishipyTwitterのAPIを使うまでの手順を解説します。いいねの数や、リツイートの数をAPIで取得できるので、SNSを用いたマーケティング等にも活かしたいですね。1. Twitter APIとは?APIとは、「アプ...(続く)
nishipy.com
前回得た以下の情報を使って、APIを使っていきます。
- API key
- API secret key
- Access token
- Access token secret
1.3. 注意
この記事を書いている時点では、500ツイートくらいしかしていません。
標本数が少ないため、有意義な考察ができていませんが、暖かく見守ってください。
2. 自分(@iamnishipy)の全ツイートを取得する
では早速、Twitter APIを使って、自分の全ツイートを取得してみます。
2.1. 認証情報を別ファイルで定義しておく
1.2節で取得した値は、誰にも知られてはなりません。
今回は暗号化はしませんが、間違ってクラウド上にアップロードしてしまわないように、別ファイルに書くこととします。
ここでは、[twitter_api.py]という名前のファイルにしてみます。
|
1 2 3 4 |
CONSUMER_KEY = # '取得した値' CONSUMER_SECRET_KEY = # '取得した値' ACCESS_TOKEN = # '取得した値' CCESS_TOKEN_SECRET = # '取得した値' |
2.2. Twitter APIの認証情報を設定する
以下では、先ほどとは別ファイルで行います。
[twitter_api.py]とこれから作成するファイルは、同一フォルダに入れることに、注意してください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import tweepy import csv import seaborn as sns sns.set(style="whitegrid") import pandas as pd import twitter_api # 先ほど作った変数をインポート # 認証情報を、別ファイルから取得 key = twitter_api.CONSUMER_KEY key_secret = twitter_api.CONSUMER_SECRET_KEY token = twitter_api.ACCESS_TOKEN token_secret = twitter_api.ACCESS_TOKEN_SECRET # 認証情報を設定 auth = tweepy.OAuthHandler(key, key_secret) auth.set_access_token(token, token_secret) api = tweepy.API(auth) |
2.3. 自分のツイートを全て取得する
認証情報を設定できたら、自分のツイートを全て取得してみます。
tweepy.user_timeline()を使いますが、一度に200件しか取得できないようなので、少し工夫します。こちらのコードを参考にしました。
→ https://gist.github.com/yanofsky/5436496
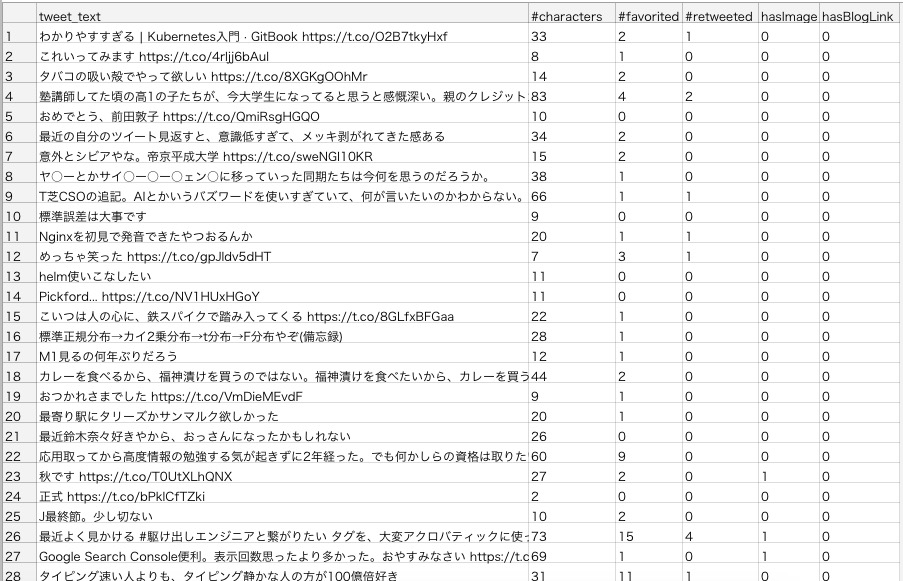
各ツイートに関して、以下のような情報を取得し、csvに書き出します。
- ツイートの内容
- ツイートした文字数(URL除く)
- いいね数
- リツイート数
- 画像付きか否か
- ブログへのリンク付きか否か
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 全ツイートを入れる空のリストを用意 all_tweets = [] # 直近の200ツイート分を取得しておく latest_tweets = api.user_timeline(count=200) all_tweets.extend(latest_tweets) # 取得するツイートがなくなるまで続ける while len(latest_tweets)>0: latest_tweets = api.user_timeline(count=200, max_id=all_tweets[-1].id-1) all_tweets.extend(latest_tweets) with open('all_tweets.csv', 'w', newline='') as f: writer = csv.writer(f) writer.writerow(['tweet_text', '#characters', '#favorited', '#retweeted', 'hasImage', 'hasBlogLink']) for tweet in all_tweets: if (tweet.text.startswith('RT')) or (tweet.text.startswith('@')): continue # RTとリプライはスキップ else: has_image = 0 # 画像付きのツイートか has_bloglink = 0 # ブログへのリンク付きのツイートか tweet_characters = tweet.text # ツイートの文字列 if 'media' in tweet.entities: has_image = 1 if len(tweet.entities['urls']) > 0: # urlは、文字数としてカウントしない tweet_characters = tweet_characters.strip(tweet.entities['urls'][0]['url']).strip() if 'nishipy.com' in tweet.entities['urls'][0]['display_url']: has_bloglink = 1 writer.writerow([tweet.text, len(tweet_characters), tweet.favorite_count, tweet.retweet_count, has_image, has_bloglink]) |
こんな感じで出力されます。
3. “いいね”されやすいツイートについて
ここからは、簡単にデータをみていきます。
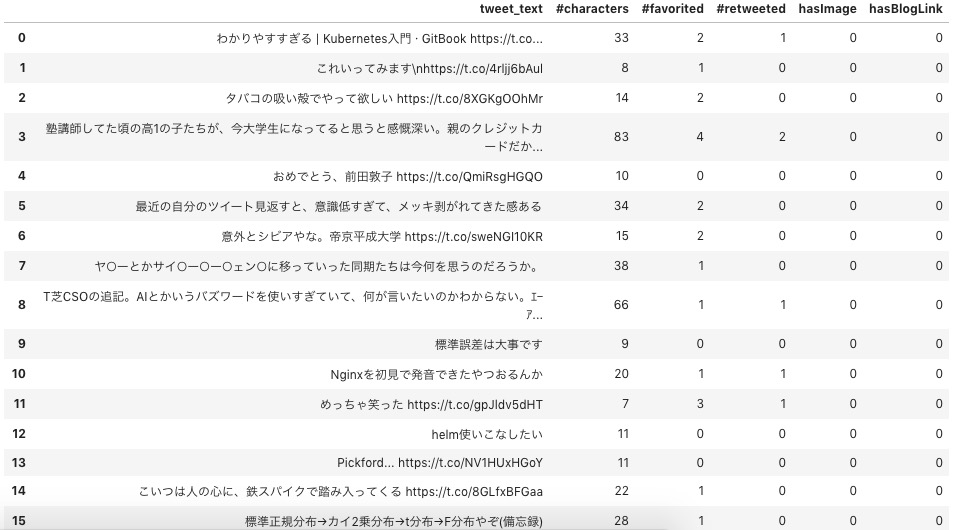
3.1. DataFrameにぶち込む
|
1 2 3 |
CONSUMER_KEY = # '取得した値' df = pd.read_csv('all_tweets.csv') df[:16] |
|
1 2 |
CONSUMER_KEY = # '取得した値' df.describe() |

3.2. 簡単な考察
seabornの練習に、グラフを書いていきます。
(1) 文字数の多いツイートは、”いいね”数が多い?
散布図を書いてみます。
|
1 |
sns.lmplot(x="#characters",y="#favorited",data=df) |
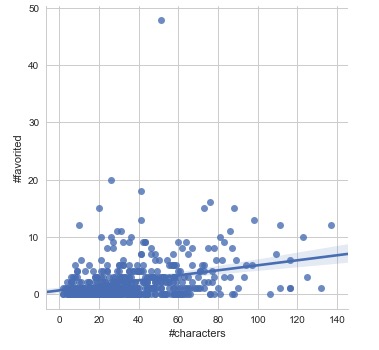
相関はない気がする。
(2) ブログへのリンク付きのツイートは、”いいね”数が多い?
平均値と標準誤差を図示します。
|
1 |
sns.barplot(x="hasBlogLink", y="#favorited", data=df) |

リンク付きの方が、”いいね”数は多そう。
(3) 画像付きのツイートは、”いいね”数が多い?
同様に、平均値と標準誤差を図示します。
|
1 |
sns.barplot(x="hasImage", y="#favorited", data=df) |

画像付きのツイートは、”いいね”数がかなり多そうです!
4. 最後に
4.1. まとめ
- Twitter APIを使った
- 画像付きツイートの”いいね”が多いことがわかった
- Twitterアナリティクスがいかに便利かわかった
4.2. これからやりたいこと
- いっぱいツイートして、標本数を多くする
- “いいね”数を予測できるモデルを構築する
- 特徴量をひらめき、取得方法を実装する

[Python]モンテカルロ法で円周率を近似してみる
NishipyPython歴2ヶ月位の私が、とあるきっかけで、モンテカルロ法を思い出しました。懐かしいのでPythonで実装してみて、円周率(π)を近似してみます。図を描く練習にもなりました。1. きっかけPythonを...(続く)
nishipy.com

404 NOT FOUND | Nishipy Notes
nishipy.com
以上


コメント