

おなじみのTitanicチュートリアルをやってみました。
実際にやっていたのは数ヶ月前ですが、備忘録として書いておきます。
1. はじめに
1.1. Kaggleとは
Kaggleとは、データ分析コンぺです。Twitterに強い人がたくさんいます。
Kaggleは企業や研究者がデータを投稿し、世界中の統計家やデータ分析家がその最適モデルを競い合う、予測モデリング及び分析手法関連プラットフォーム及びその運営会社である。 モデル作成にクラウドソーシング手法が採用される理由としては、いかなる予測モデリング課題には無数の戦略が適用可能であり、どの分析手法が最も効果的であるか事前に把握することは不可能であることに拠る。 2017年3月8日、GoogleはKaggle社を買収すると発表した。[Wikipedia]
1.2. 今回やること
Kaggle初心者がやるチュートリアルのようなコンペに参加します。
Titanic号の生存者を予測するモデルを作ります。詳細はこちら。

2. データセットを眺める
2.1. データの概要
では早速、コンペに参加してみます。与えられたデータの変数は、以下の通りです。
survivalを予測するのが目標です。
| Variable | Definition | Key |
|---|---|---|
| Survival | Survival | 0 = No, 1 = Yes |
| Pclass | Ticket class | 1 = 1st, 2 = 2nd, 3 = 3rd |
| Sex | Sex | |
| Age | Age in years | |
| SibSp | # of siblings / spouses aboard the Titanic | |
| Parch | # of parents / children aboard the Titanic | |
| Ticket | Ticket number | |
| Fare | Passenger fare | |
| Cabin | Cabin number | |
| Embarked | Port of Embarkation | C = Cherbourg, Q = Queenstown, S = Southampton |
詳しい説明を、以下に抜粋しておきます。
- Pclass: A proxy for socio-economic status (SES)
1st = Upper
2nd = Middle
3rd = Lower -
Age: Age is fractional if less than 1. If the age is estimated, is it in the form of xx.5
-
SibSp: The dataset defines family relations in this way…
Sibling = brother, sister, stepbrother, stepsister
Spouse = husband, wife (mistresses and fiancés were ignored) -
Parch: The dataset defines family relations in this way…
Parent = mother, father
Child = daughter, son, stepdaughter, stepson
Some children travelled only with a nanny, therefore parch=0 for them.
2.2. データの確認
モジュールのインポート
使いそうなモジュールはインポートしておきます。
|
1 2 3 4 5 6 7 8 9 |
import numpy as np import scipy as sp import pandas as pd import matplotlib.pyplot as plt import matplotlib as mpl import seaborn as sns sns.set() |
データの読み込み
trainデータセットと、testデータセットを読み込みます。
|
1 2 3 |
train_df = pd.read_csv("train.csv") test_df = pd.read_csv("test.csv") |
trainデータセットの確認
trainデータセットについて、さらに確認します。
|
1 2 |
train_df.info() |

データの考察
Titanicで生存できたか否かに効きそうなパラメータについて、確認していきます。
例えば、性別ごとの生存率を確認したい場合は、以下のようにしました。
女性の方が助かりやすかったことがわかります。
|
1 2 |
train_df.groupby('Sex')['Survived'].mean() |

社会的地位(Pclass)や乗船した港(Embarked)も、生存できたか否かに影響しそうです。
|
1 2 |
train_df.groupby('Pclass')['Survived'].mean() |

|
1 2 |
train_df.groupby('Embarked')['Survived'].mean() |

データの基本統計量
DataFrameに対して、describe()すれば、基本統計量を見ることができます。
平均や分散、四分位数などを確認できます。
|
1 2 |
train_df.describe() |

質的データについては、describe(include=['O'])とします。
|
1 2 |
train_df.describe(include=['O']) |

データの可視化
以下のように、データを可視化するのが特に有効なようです。
Google先生に聞けば、良い記事がたくさん出てくるので、そちらを参照ください。。
|
1 2 3 |
# 性別と社会的地位ごとの生存率 sns.barplot(x="Sex", y="Survived", hue="Pclass", data=train_df) |

|
1 2 3 |
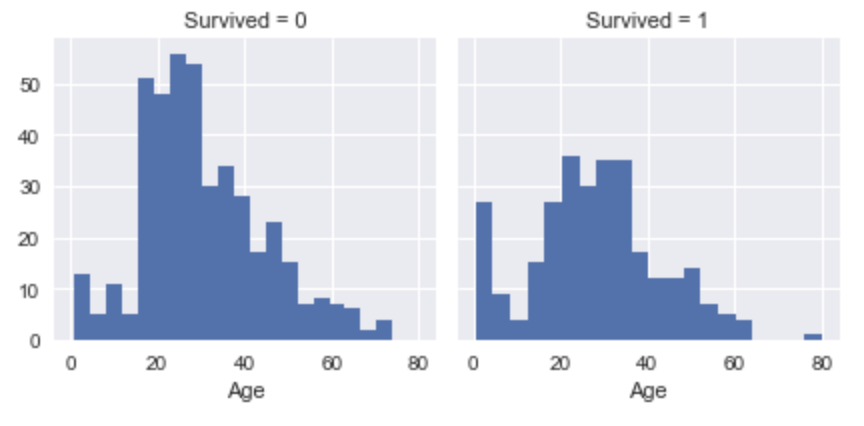
# 年齢別の生存可否 sns.FacetGrid(train_df, col='Survived').map(plt.hist, 'Age', bins=20) |
|
1 2 3 4 5 |
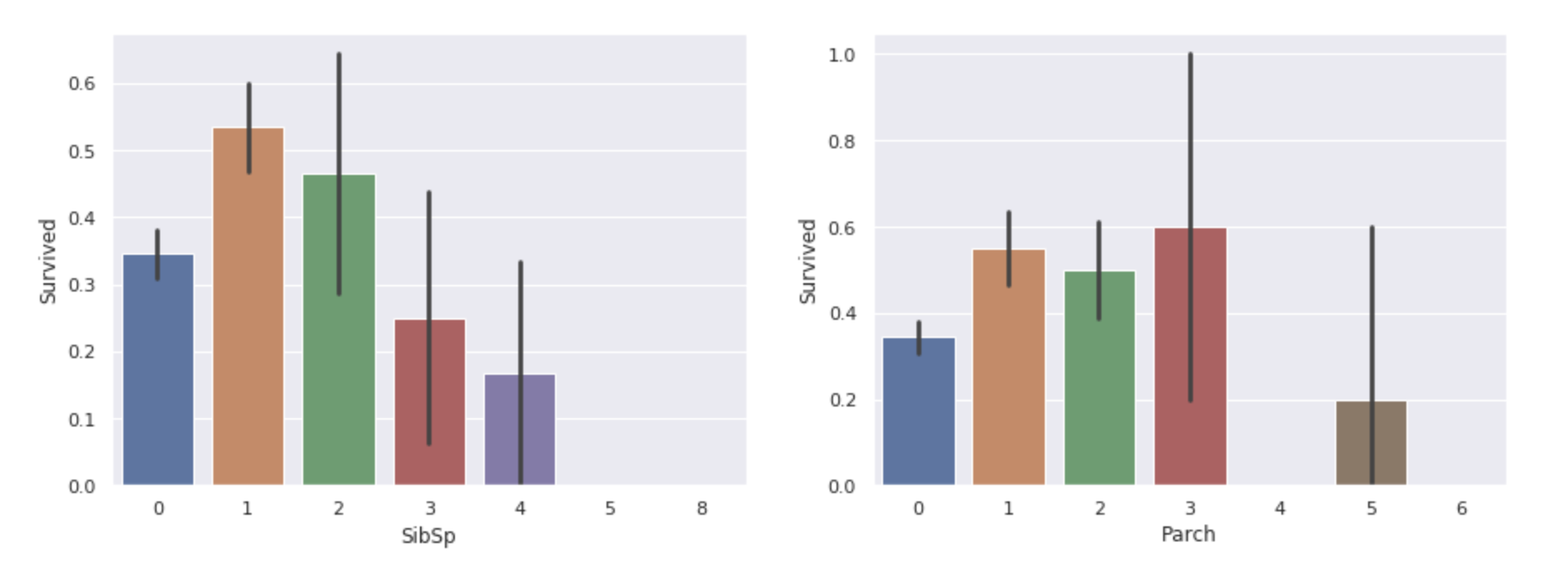
# 一緒に乗船した家族の数と、生存率 fig,ax = plt.subplots(1,2,figsize=(15,5)) sns.barplot(x="SibSp", y="Survived", data=train_df, ax=ax[0]) sns.barplot(x="Parch", y="Survived", data=train_df, ax=ax[1]) |
3. データの前処理
予測モデルを構築するために、データの前処理を行います。
3.1. 特徴量を排除する
与えられた特徴量のうち、欠損値が多いものや、扱いにくそうなものを排除します。
今回は、TicketとCabinをdropしました。
|
1 2 3 |
train_df = train_df.drop(['Ticket', 'Cabin'], axis=1) test_df = test_df.drop(['Ticket', 'Cabin'], axis=1) |
3.2. 単純な前処理
Age
欠損値に対する処理を行います。今回は、Medianで置き換えます。
|
1 2 3 4 |
# medianで置き換える train_df['Age'].fillna(train_df['Age'].median(), inplace=True) test_df['Age'].fillna(train_df['Age'].median(), inplace=True) |
また、グラフでの可視化から、年齢層ごとに生存率がかなり違いそうでした。
そこで、Ageについては、年齢の数値ではなく、年齢層ごとにカテゴリー分けすることにしました。
|
1 2 3 |
for dataset in [train_df, test_df]: dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0 dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1 dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2 dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3 dataset.loc[ dataset['Age'] > 64, 'Age'] = 4 |
Sex
いま特徴量Sexには、maleかfemaleが入っています。
それぞれ、’0’と’1’が対応するようにmapし、ダミー変数とします。
|
1 2 3 4 |
sex_mapper = {'male': 0, 'female': 1} train_df['Sex'] = train_df['Sex'].map(sex_mapper).astype(int) test_df['Sex'] = test_df['Sex'].map(sex_mapper).astype(int) |
Embarked
まず、欠損値に対する処理を行います。
事前に調べたところ、’S’がもっとも多いので、欠損値をこの値で置き換えます。
|
1 2 3 |
train_df['Embarked'].fillna(('S'), inplace=True) test_df['Embarked'].fillna(('S'), inplace=True) |
さらに、Sexと同様にダミー変数とします。
|
1 2 3 4 |
embarked_mapper = {'C': 0, 'Q': 1, 'S': 2} train_df['Embarked'] = train_df['Embarked'].map(embarked_mapper).astype(int) test_df['Embarked'] = test_df['Embarked'].map(embarked_mapper).astype(int) |
3.3. 少し苦労した前処理
Name
Nameも扱いにくい特徴量のため、dropすることを検討しましたが、
有名なKernelを調べたところ以下のようにカテゴリー分けすると使えそうです。勉強になります。
まず、頭についている敬称(?)により、新たな特徴量Titleを作ります。
|
1 2 3 4 5 |
for dataset in [train_df, test_df]: dataset['Title'] = dataset.Name.str.extract('([A-Za-z]+)\.', expand=False) pd.crosstab(train_df['Title'], train_df['Sex']) |
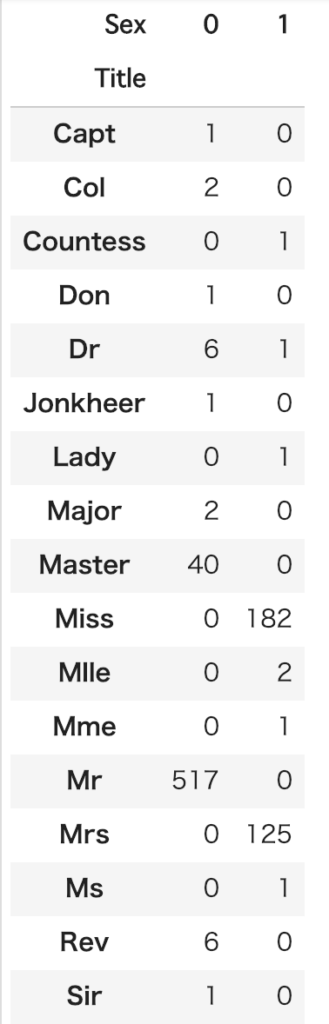
次に敬称でカテゴリー分けし、mapしてダミー変数とします。Nameはもう不要なので、dropします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# Titleをカテゴリー分け for dataset in [train_df, test_df]: dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess','Capt', 'Col', 'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare') dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss') dataset['Title'] = dataset['Title'].replace('Ms', 'Miss') dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs') # ダミー変数化 title_mapper = {'Master': 0, 'Miss': 1, 'Mr': 2, 'Mrs': 3, 'Rare': 4} train_df['Title'] = train_df['Title'].map(title_mapper).astype(int) test_df['Title'] = test_df['Title'].map(title_mapper).astype(int) # Nameは不要 train_df = train_df.drop(['Name'], axis=1) test_df = test_df.drop(['Name'], axis=1) |
Fare
まず、欠損値をMedianで埋めます。
|
1 2 |
test_df['Fare'].fillna(train_df['Fare'].median(), inplace=True) |
最初はこのまま予測モデルを作っていましたが、スコアがよくありませんでした。
そこで、Kernelを参考にして、Fareについてもカテゴリー分けすることにしました。
四分位数を考慮して、Fareをカテゴリ分けします。
|
1 2 3 4 |
for dataset in [train_df, test_df]: dataset.loc[ dataset['Fare'] <= 7.91, 'Fare'] = 0 dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1 dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2 dataset.loc[ dataset['Fare'] > 31, 'Fare'] = 3 dataset['Fare'] = dataset['Fare'].astype(int) |
3.4. 新たな特徴量’isAlone’の追加
一緒に乗船した家族の有無が、生存率に影響しそうです。
そこで、isAloneという特徴量を追加してみます。
|
1 2 3 4 |
for dataset in [train_df, test_df]: dataset['isAlone'] = 0 dataset.loc[ train_df['Parch'] + train_df['SibSp'] == 0, 'isAlone'] = 1 |
4. モデルの構築と予測データ提出
4.1. データの準備
訓練データとテストデータ
訓練用のデータと正解ラベル、テスト用のデータもを準備します。
|
1 2 3 4 5 |
X_train = train_df.drop(['Survived'], axis=1) y_train = train_df['Survived'].values X_test = test_df.copy() |
スケール変換
スケール変換して、データの範囲を揃えます。
ここでは、sklearn.preprocessing.MinMaxScalerによって、[0,1]区間に入るように変換します。
|
1 2 3 4 5 6 7 8 |
from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() scaler.fit(X_train) X_train_scaled = scaler.transform(X_train) # 注意: X_testにも、X_trainにfitさせたscalerを使うこと X_test_scaled = scaler.transform(X_test) |
4.2. 学習と予測
モデル構築と学習
今回は、ランダムフォレストsklearn.ensemble.RandomForestClassifierを用います。
|
1 2 3 4 5 6 7 8 9 10 11 |
from sklearn.model_selection import GridSearchCV from sklearn.ensemble import RandomForestClassifier param_grid = {'n_estimators': [400], 'max_depth': [5, 6, 7, 8, 9]} grid_search = GridSearchCV(RandomForestClassifier(), param_grid) grid_search.fit(X_train_scaled, y_train) print("best params: {}".format(grid_search.best_params_)) print("best score: {}".format(grid_search.best_score_)) |

予測
上で学習したモデルを用いて、テストデータの生存可否について予測します。
|
1 2 3 4 5 |
PassengerId = np.array(X_test["PassengerId"]).astype(int) my_prediction = grid_search.best_estimator_.predict(X_test_scaled) my_solution = pd.DataFrame(my_prediction, PassengerId, columns = ["Survived"]) my_solution.to_csv("my_solution_rf.csv", index_label = ["PassengerId"]) |
Submit
csvファイルとして出力した予測データを、Kaggleのwebページから提出します。
これまで説明してきた手順だと、Scoreは0.82くらいだったと思います。
以上で、Kagglerとして押さえておくべき一連の流れを経験できたと思います。
5. 最後に
5.1. 今回できたこと
- データ取得から予測、提出までを経験しました。
- Kaggleの入口に立ちました
- Kernelがよい教材であることがわかりました
5.2. これからやりたいこと
- 物怖じせず、コンペに参加します
以上
コメント