
はじめに
この記事について
Kaggleコンペに初めて参戦し銅メダルを取ったことについて書きます。Public LB銀圏から最終的には銅メダルになってしまい悔しい思いもしましたが、主催者やKaggleコミュニティの皆さんのおかげでとても楽しめました!
なお本記事では、技術的な話はあまりしません(できません)。Kaggleコンペへの取り組み方や勉強したこと、チームメイトとのコミュニケーションに関する話題を中心に書くつもりです。
初心者感・不勉強感が滲み出ている場合は、暖かく見守っていただくか、Twitterなどでアドバイス頂けると幸いです!
スペック
Kaggleコンペ参戦のブログ記事を見ていると、参考としてスペック書いている方が多いです。そこでまずは自己紹介をさせてください。スペックはこんな感じです。
- Twitter @iamnishipy
- 非情報系院卒社会人6年目ガチアラサー
- 某JTC → 某外資系ソフトウェアベンダー
- 【退職エントリ】新卒入社した日系大企業を辞めるということ(ブログ)
- 仕事でKubernetesとかAnsibleとかLinuxを触ってるエンジニア
- 分類するなら、インフラエンジニア(?)
- 3年くらい前にAIブームに乗っかろうとした時期もあった
- Kaggleはその頃アカウント作成
- Taitanicで遊んだ
- Titanicの生存者予測を通して、Kaggleの流れを体験してみた(ブログ)
- MSのMalwareコンペに試しに登録
- 公開Notebookを眺めて、いくつか実行しただけ
- 本も何冊か読んだ
- 試しに遊んだりもした
- Kaggleはその頃アカウント作成
- 東大松尾研「社会人向けデータサイエンスオンライン講座」を修了
参戦記
コンペ概要
今回参加したのは、CommonLit Readability Prizeというコンペです。詳細については、以下のリンクを参照ください。

雰囲気で要約すると、アメリカの3〜12年生(小3〜高3)の子どもが授業で読む英語の文章の”複雑さ”を評価するアルゴリズムを開発するコンペでした。
チーム
友人で立派なKaggle Expertであるしぃたけ(@cpp_take)とチームを組んで参加しました。私も彼もNLP(自然言語処理)は初めてだったので、各々が公開NotebookやDiscussionを見て勉強し、適宜共有しながら進めていきました。
私のような飽き性の人間にとって、チームでの参加はありがたかったです。適宜コミュニケーションを取ることで、途中で諦めることなく、最後まで走り切ることができました。
役割分担
今回が初コンペである私にとって、チームで参戦するのも当然初めてです。どのように役割分担するのが正解かわかりませんが、お互いやることが重複しないように、概ね以下のような役割で進めていきました。私にはGitやLinuxの知識があり、彼にはKaggleの知識やコンペ参加経験があったので、そこをGive&Takeできた点も良かったです。
- nishipy(私)
- よさげな公開Notebookのコードの理解・改善・アンサンブル
- 主にRoBERTaの単独モデルを改善
- アンサンブルはたまに
- GitHubやLinuxの使い方を教える
- しぃたけ(チームメイト)
- よさげな公開Notebookのコードの理解・改善・アンサンブル
- Stackingを実装など
- nishipy作成のモデルと組み合わせて、最終的なアンサンブルを検討
- Kaggleの使い方、戦い方を教える
コミュニケーション
チームとして、お互いが今やっていることを共有するために、コミュニケーションが重要です。
チャットやビデオ通話には、Discordを使いました。実はあんまり使ったことがなかったのですが、普段のコミュニケーションを1つのアプリにまとめることができて便利でした。
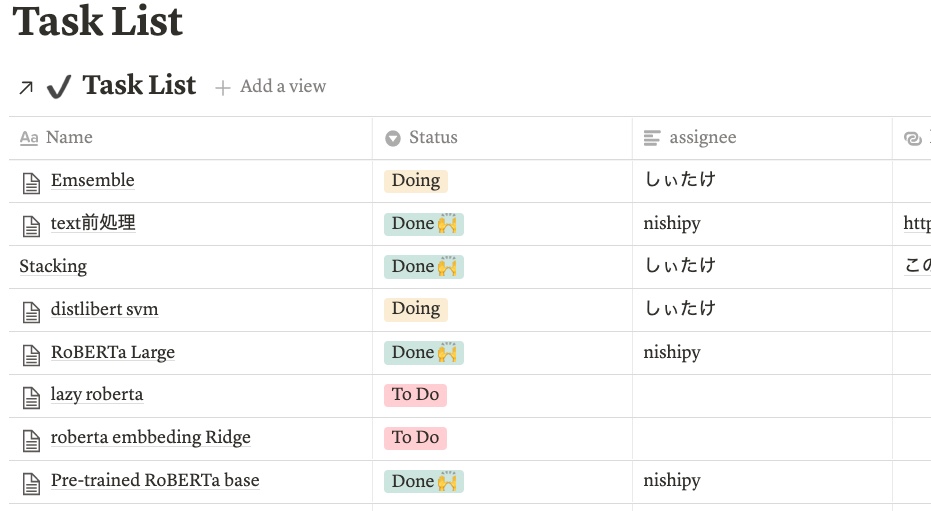
Notionでは、お互いがやっていることやモデルのCVスコアを記述しました。ただのおしゃれメモ帳ではなく、タスクリストにもなるので、かなり重宝しました。例えば、ある日のタスクリストはこんな感じです。
開発環境
我が家にはMacbookしかないので、開発環境には少し苦労しました。はじめはKaggle上で開発していたのですが、すぐにGPUのクォータに引っかかります。
そこで、Google Colab Proを契約してみました。月1000円くらいとかなり安いですが、GPUを使ったセッションを3つまで同時に実行できて最高でした。ただ、2ヶ月目はなぜかGPUセッションが1つまでしか実行できなくなりました。Colab Proの仕様、よくわからない…
勉強方法
コンペに参加したおかげでいろいろ勉強がはかどりました。
書籍
まず、こちらの積読本を1つ消化しました。Kaggleのことや、Kaggleでよく使う一般的な機械学習の知識を効率よく勉強できました。
NotebookとDiscussion
コンペに特化した勉強には、やはり公開されているNotebookやDiscussionを読み込むのが一番です。素晴らしいNotebookやDiscussionを共有してくださったKaggleコミュニティの皆さん、本当にありがとうございました!彼ら/彼女らのおかげでたくさんのことを学びました。
YouTube
ググってもわからないことが出てきたときは、YouTubeの動画がとてもありがたいです。最近は日本語の動画も充実しています。例えば、TransformerのMulti-Head Attentionを以下の動画で勉強しました。わかりやすすぎる…
ドキュメントとGitHub
RoBERTaを多用するコンペだったので、以下のドキュメントやGitHubも有用でした。

提出するモデルの選択
このコンペはtrainデータが比較的少ない(2800個くらい)上、色々実験していく中でCVとPublic LBのスコアに乖離する傾向が見られました。そこでshake-down対策として、提出するモデル2つは、1つ目にPublic LBで最もスコアがいいものを、2つ目にCVで最もスコアがいいものを選ぶことにしました。
最終結果
その他なんやかんやあり、最終的には銅メダルが確定しました。
メダル確定してる〜はじめのいっぽ https://t.co/xbEKtBe8Qv pic.twitter.com/XuthZ6wE2w
— nishipy (@iamnishipy) August 10, 2021
解法の詳細についてはNotebookを公開しているので、よければご覧ください。

反省点
初めてコンペに参加してみて、反省点は山ほどありますが一部書き出してみます。
コード管理がダサい
Google Driveとほんの一部GitHubを用いて管理していましたが、以下のように、.ipynbファイルをほぼフラットなディレクトリに並べていたのでダサかったです。共通部分は.pyで分けたり、ディレクトリ構成を再検討したり、改善すべき点はやまのごとし。上位の方が公開しているGitHubリポジトリをいくつか見つけたので、次回に向けて参考にさせていただきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
commonlit $ tree . ├── embedding-svm [...] ├── kaggle.json ├── roberta-base │ ├── dataset-metadata.json │ ├── pre-trained-roberta-BASELINE.ipynb │ [...] │ ├── requirements.txt │ └── trust-cv │ └── pre-trained-roberta-BASELINE-Kfold.ipynb ├── roberta-large │ ├── dataset-metadata.json │ ├── old │ │ ├── roberta-large-Kfold-Sche-Epoch.ipynb │ │ └── roberta-large-Kfold-old.ipynb │ ├── requirements.txt │ ├── roberta-large-BASELINE.ipynb │ [...] │ ├── roberta-large-Sche-BEST-stratiKfold.ipynb │ ├── roberta-large-Sche-BEST.ipynb │ └── roberta-large-Sche.ipynb ├── train.csv └── train_stratiKfold.csv |
アンサンブルの検討不足
アンサンブルするモデルの数や重みについて、もう少し検討しても良かったと思います。上位の解法では10~20個以上のモデルをアンサンブルしているものもあるし、重みについても1/100の単位まで試行錯誤されています。
NotebookやDiscussion以外の情報収集・実装してない
時間が許せば、公開されているNotebookやDiscussion以外でも情報収集を行い、自分で実装までやりたいですね。今回はみんなRoBERTa使ってそうだからと言って、RoBERTaに重きを置きすぎた気がします。結局それが一番効率よい戦い方なのですが、他のモデルもいろいろ試すともっと楽しめそうです。
おわりに
初めてのKaggleコンペに参加し、銅メダルをもらった経験をまとめました。次のコンペ参加はいつになるかわかりませんが、とりあえずKaggle Expert目指してゆるゆるやりたいと思います。
最後まで読んでくださってありがとうございます。Kaggle界隈の皆さま、引き続きTwitter(@iamnishipy)で絡んで頂けると嬉しいです。
一緒に参加したしぃたけの参戦記はこちらです。

以上.


コメント