
1. はじめに
1.1. 背景
遡ること2014年、ブラジルでサッカーW杯が開催されていました。サッカーの母国イングランド代表チームも、もちろん出場しています。強豪マンチェスターユナイテッドでいじられキャラとして人気のDFクリス・スモーリング選手も、イングランド代表のメンバーの一人でした。
W杯特需を狙ったお土産製造会社は、当然のようにこの人気者のグッズを製作しました。

Google画像検索でスモーリング選手の検索し、それをプリントしたマグカップを商品化したようです。しかし、なぜか当時のアメリカ大統領であるバラク・オバマの写真を印刷してしまいました。この凡ミスは、当時日本のサッカーメディアでも多く取り上げられており、私自身爆笑していたのを覚えています。
1.2. 今回やりたいこと
このような悲劇は、二度と繰り返されてはなりません。
私は強い使命感を覚え、スモーリング/オバマ判別器を実装することに決めたのでした。
イメージはこちら。今回は、学習の準備として、画像収集と顔の検出を行います。
今読んでる本が終わったら、スモーリング/オバマ判別器実装したい pic.twitter.com/LdFlFqQ1tk
— nishipy (@iamnishipy) 2018年10月29日
1.3. 補足
本項で言うスモーリングとオバマについて、補足しておきます。
スモーリング

クリストファー・ロイド・”クリス”・スモーリング(Christopher Lloyd “Chris” Smalling, 1989年11月22日 – )は、イングランド出身のサッカー選手。ポジションはセンターバックでありマンチェスター・ユナイテッドに所属し、イングランド代表にも選出されている。…[Wikipwdia]
オバマ

バラク・フセイン・オバマ2世(Barack Hussein Obama 、1961年8月4日 – )は、アメリカ合衆国の政治家である。民主党所属。上院議員(1期)、イリノイ州上院議員(3期)、第44代アメリカ合衆国大統領を歴任した。アフリカ系[注 1]としてアメリカ合衆国史上3人目となる民選上院議員(イリノイ州選出、2005年 – 2008年[注 2])。また、アフリカ系、20世紀後半生まれ、ハワイ州出身者としてアメリカ合衆国史上初となる大統領である。…[Wikipedia]
2. 画像収集
まずは、訓練データとしてスモーリングとオバマの画像を収集します。
Google画像検索で表示された画像を、それぞれ500枚ずつ収集することにします。
2.1. スクレイピング
Qiitaにあったこちらの記事を見れば、すぐに出来ました。ありがとうございます。
[Qiita]API を叩かずに Google から画像収集をする→
以下のコードは、引用です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 |
import json import os import sys import urllib from bs4 import BeautifulSoup import requests class Google: def __init__(self): self.GOOGLE_SEARCH_URL = 'https://www.google.co.jp/search' self.session = requests.session() self.session.headers.update( {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:10.0) Gecko/20100101 Firefox/10.0'}) def search(self, keyword, maximum): print('begin searching', keyword) query = self.query_gen(keyword) return self.image_search(query, maximum) def query_gen(self, keyword): # search query generator page = 0 while True: params = urllib.parse.urlencode({ 'q': keyword, 'tbm': 'isch', 'ijn': str(page)}) yield self.GOOGLE_SEARCH_URL + '?' + params page += 1 def image_search(self, query_gen, maximum): # search image result = [] total = 0 while True: # search html = self.session.get(next(query_gen)).text soup = BeautifulSoup(html, 'lxml') elements = soup.select('.rg_meta.notranslate') jsons = [json.loads(e.get_text()) for e in elements] imageURLs = [js['ou'] for js in jsons] # add search result if not len(imageURLs): print('no more images') break elif len(imageURLs) > maximum - total: result += imageURLs[:maximum - total] break else: result += imageURLs total += len(imageURLs) print('found', str(len(result)), 'images') return result def main(): google = Google() if len(sys.argv) != 3: print('invalid argment') print('> ./image_collector_cui.py [target name] [download number]') sys.exit() else: # save location name = sys.argv[1] data_dir = 'data/' os.makedirs(data_dir, exist_ok=True) os.makedirs('data/' + name, exist_ok=True) # search image result = google.search( name, maximum=int(sys.argv[2])) # download download_error = [] for i in range(len(result)): print('downloading image', str(i + 1).zfill(4)) try: urllib.request.urlretrieve( result[i], data_dir + name + '/' + str(i + 1).zfill(4) + '.jpg') except: print('could not download image', str(i + 1).zfill(4)) download_error.append(i + 1) continue print('complete download') print('├─ download', len(result)-len(download_error), 'images') print('└─ could not download', len( download_error), 'images', download_error) if __name__ == '__main__': main() |
2.2. 収集した画像
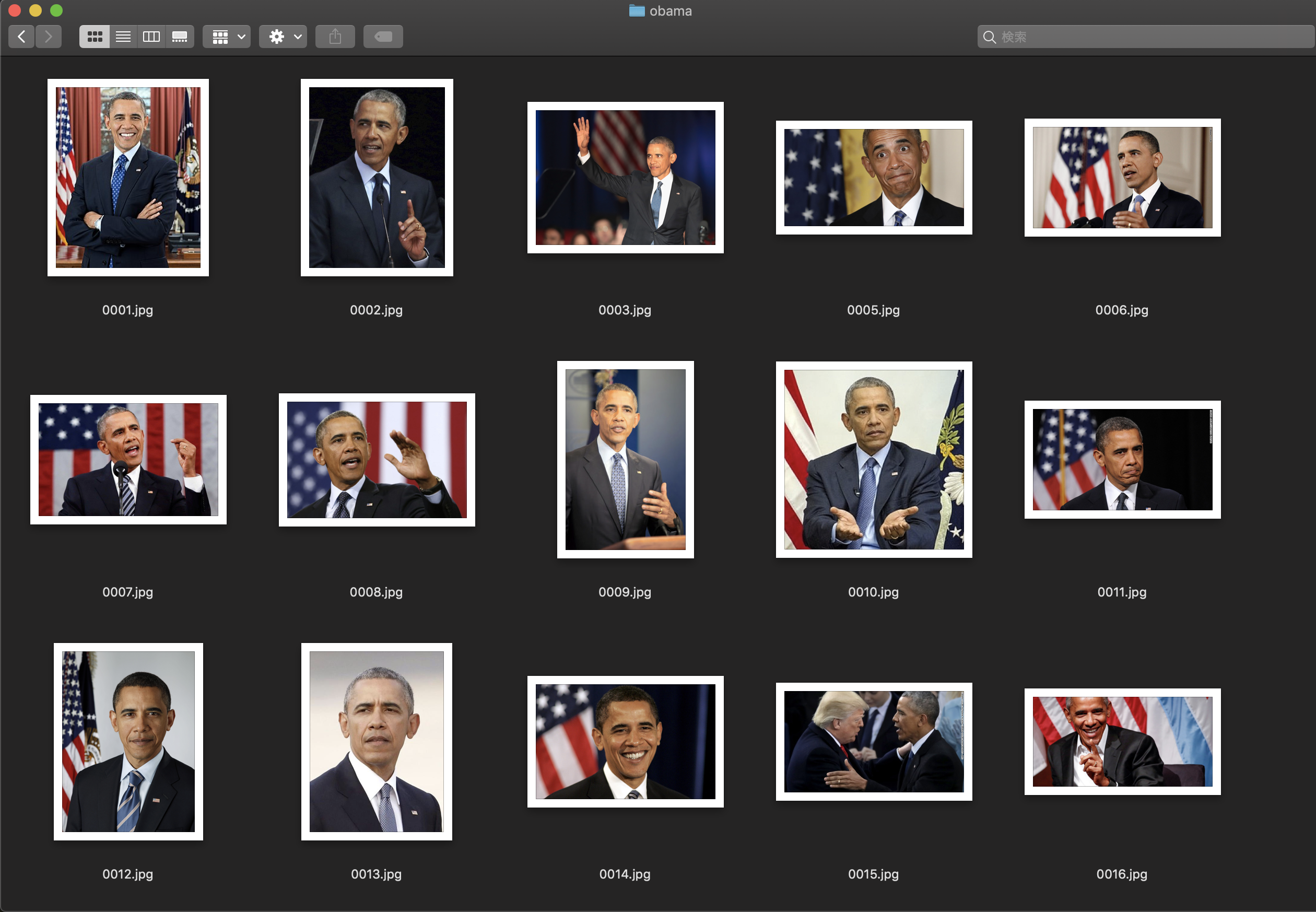
以下のように、保存されます。何らかの理由でダウンロード出来なかったものはスキップされます。
本人の写真が多いですが、別人の写真もあります。
スモーリング
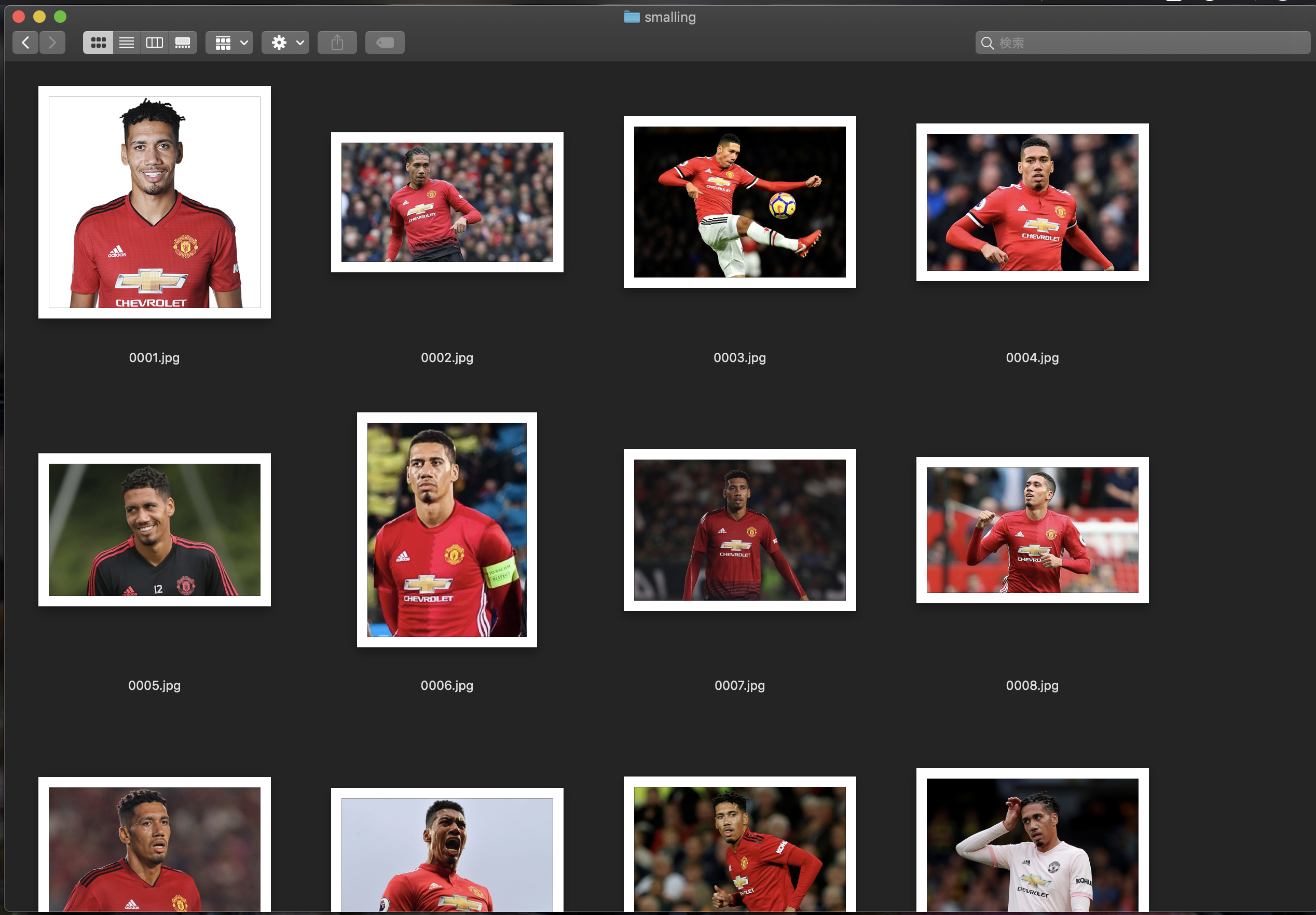
オバマ
2.3. 別人の画像を取り除く
別人の画像は、仕方ないので手作業で取り除きました。
かなり枚数が減ってしまいました。
ダウンロード出来なかった画像と、ダウンロード出来たが別人だった画像を取り除いた結果、それぞれの画像数は以下のようになりました。
- オバマ:394枚
- スモーリング:390枚
3. 顔検出
収集した画像から、顔を検出し、その部分だけをトリミングして訓練データとします。
OpenCVを使いました。こちらの記事が参考になります。

3.1. トリミングして、保存
先ほど収集した画像から、人の顔だと認識されたもの全てをトリミングして保存していきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
def make_mydir(path): if not os.path.isdir(path): os.makedirs(path) def face_detector(image_dir, image_files, save_dir, cascade_path): make_mydir(save_dir) for im in image_files: image_path = os.path.join(image_dir, im) print("-----------------------------------------------------------------------------------------") print(image_path) image_gs = cv2.imread(image_path) cascade = cv2.CascadeClassifier(cascade_path) facerect = cascade.detectMultiScale(image_gs, scaleFactor=1.1, minNeighbors=3, minSize=(1, 1)) i_faces = 1 if len(facerect) > 0: for rect in facerect: x = rect[0] y = rect[1] width = rect[2] height = rect[3] dst = image_gs[y:y + height, x:x + width] out_file = im.split(".")[0] + "_" + str(i_faces) + ".jpg" save_path = os.path.join(save_dir, out_file) print(save_path) cv2.imwrite(save_path, dst) i_faces += 1 else: print("No faces detected.") continue print("done...") |
上記のような関数を定義して、トリミングしました。
実行すると、トリミング後の画像が保存されます。
|
1 2 3 4 5 6 7 8 9 10 |
in_smalling_dir = "./data/smalling" in_obama_dir = "./data/obama" out_smalling_dir = "./faces/smalling" out_obama_dir = "./faces/obama" cascade_path = "/usr/local/opt/opencv/share/OpenCV/haarcascades/haarcascade_frontalface_alt2.xml" face_detector(in_smalling_dir, in_smalling_files, out_smalling_dir, cascade_path) face_detector(in_obama_dir, in_obama_files, out_obama_dir, cascade_path) |
3.2. トリミング後の画像
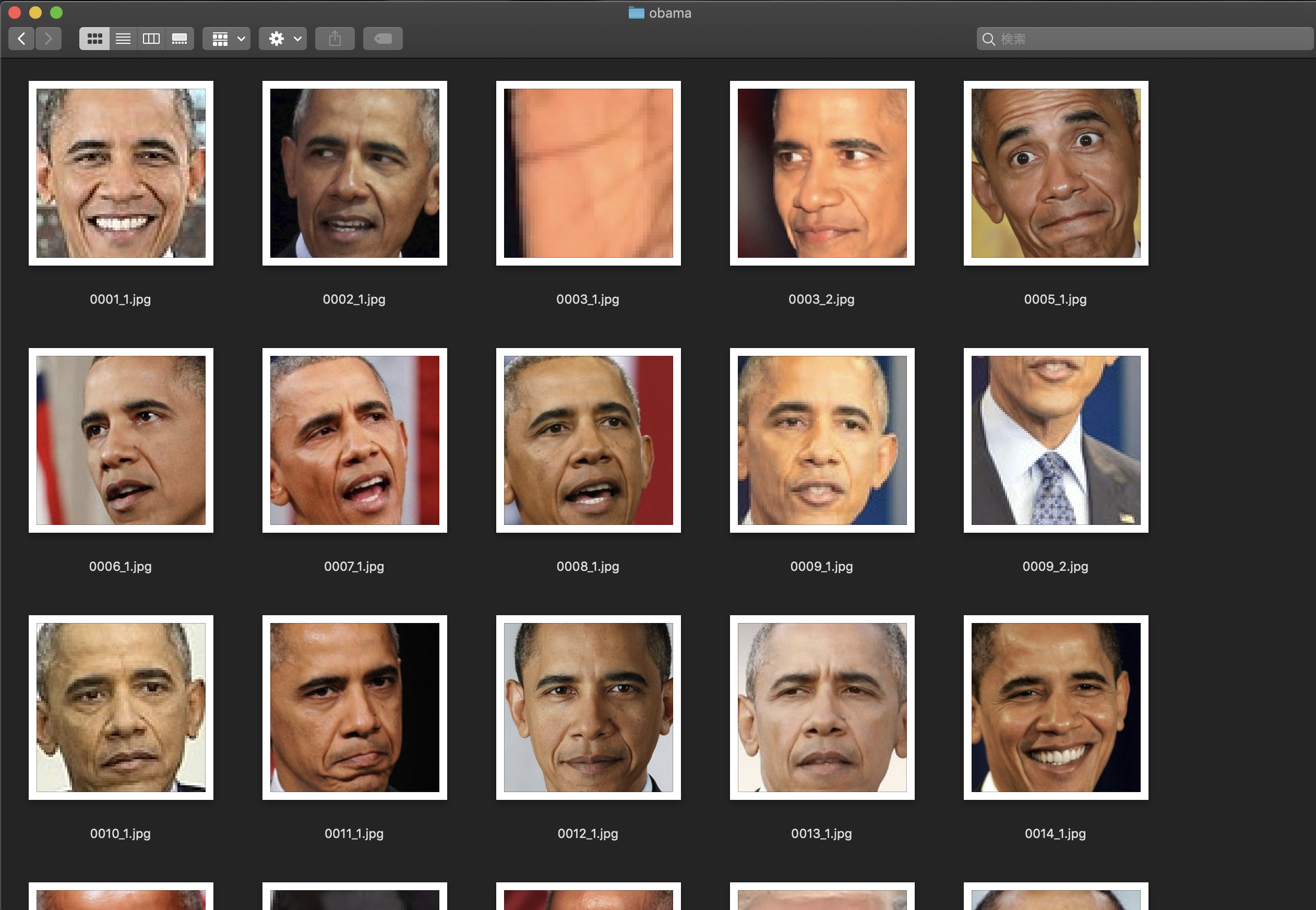
トリミングした後の画像は、以下のようになります。
別人の顔や、顔以外のものを抜き取っているため、取捨選択が必要そうです。
スモーリング
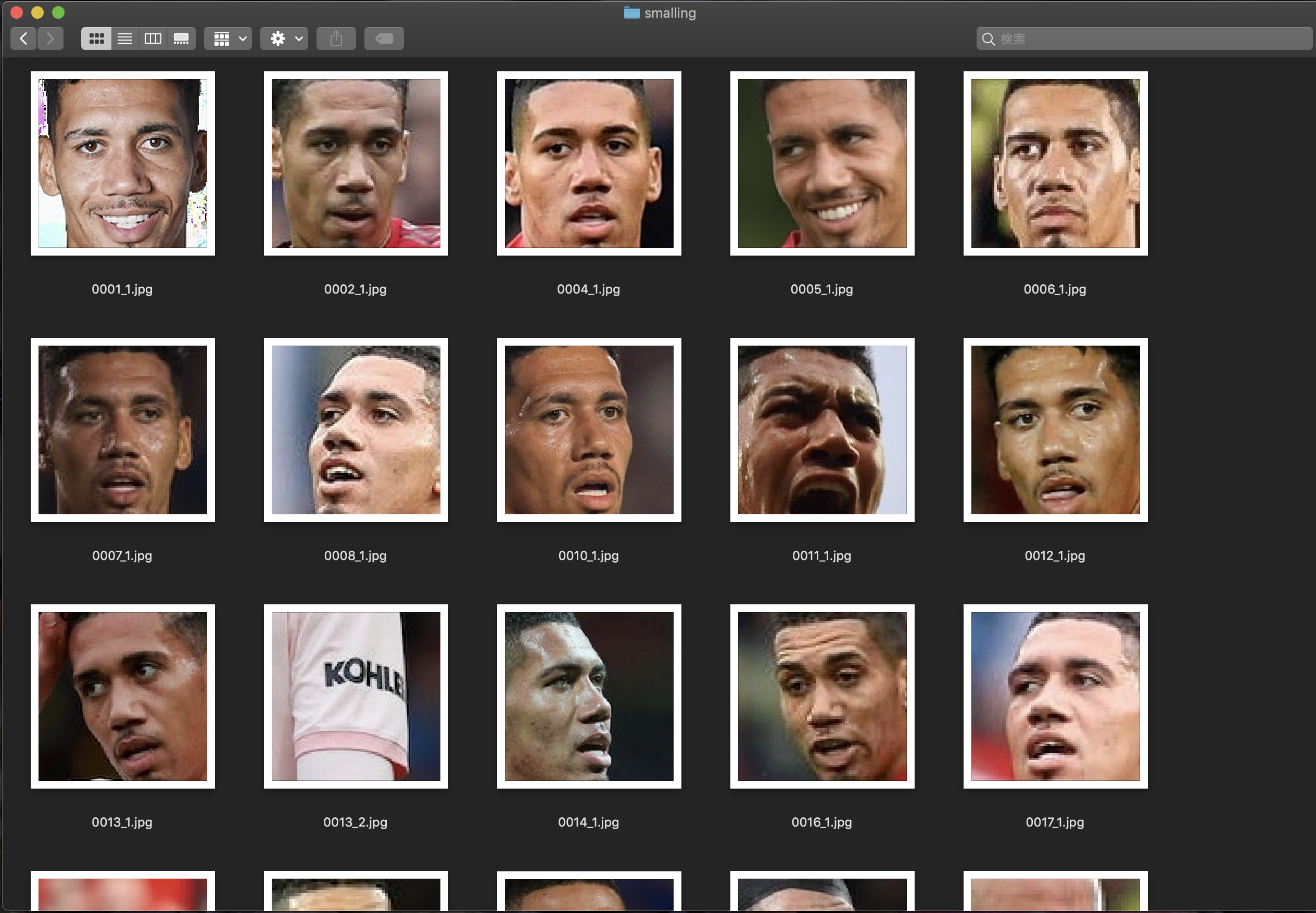
オバマ
3.3. 不要な画像を取り除く
別人の画像や、顔以外のものは仕方ないので手作業で取り除きました。
ここでも、かなり枚数が減ってしまいました。残った画像数は、以下の通りです。
- オバマ:272枚
- スモーリング:231枚
4. 最後に
4.1. 今回できたこと
- スクレイピングで画像を収集しました
- 収集した画像から顔を検出し、訓練データを作成しました
- 一部根性で解決しました
4.2. これからやりたいこと
- CNNを実装して、オバマ/スモーリング判別器を完成させる
後編に続く。

以上


コメント